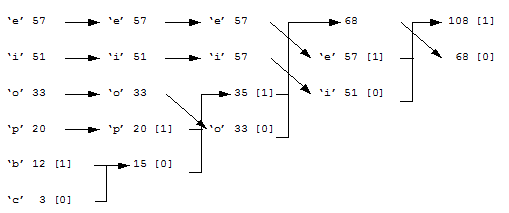
Huffman Coding[Theory] Huffman coding uses a variable length code for each of the elements within the data. This normally involves analyzing the data to determine the probability of its elements. The most probable elements are coded with a few bits and the least probable coded with a greater number of bits. This could be done on a character-by-character basis, in a text file, or could be achieved on a byte-by-byte basis for other files. The following example relates to characters. First, the textual data is scanned to determine the number of occurrences of a given letter. For example: Letter: 'b' 'c' 'e' 'i' 'o' 'p' No. of occurrences: 12 3 57 51 33 20 Next the characters are arranged in order of their number of occurrences, such as: 'e' 'i' 'o' 'p' 'b' 'c' 57 51 33 20 12 3 After this the two least probable characters are assigned either a 0 or a 1. Figure 1 shows that the least probable (‘c’) has been assigned a 0 and the next least probable (‘b’) has been assigned a 1. The addition of the number of occurrences for these is then taken into the next column and the occurrence values are again arranged in descending order (that is, 57, 51, 33, 20 and 15). As with the first column, the least probable occurrence is assigned a 0 and the next least probable occurrence is assigned a 1. This continues until the last column. When complete, the Huffman-coded values are read from left to right and the bits are listed from right to left. The final coding will be: 'e' 11 'i' 10 'o' 00 'p' 011 'b' 0101 'c' 0100
Figure 1 |
 [
[
Try an example
test t 2 ------> 2 [0] e 1 [0] --> 2 [1] s 1 [1] t e s t 0 10 11 0 hello l 2 ------ 2 [1] h 1 -----> 1 [0] ---> 3 [0] e 1 [0] ------------> 2 [1] o 1 [1] 00 01 11 11 10 h e l l o