Why do we use Bytes?

Why do we use Bytes?
And why you shouldn’t take anything for granted
Introduction
Do you think we have lost our child-like trait to ask really simple questions, as we were often told off for asking them? So when your child asks you:
Why is the sky blue?
you think … “Good question … and mumble something about the colour of the sea” .. and then they say:
Why is the sea salty?
… and you shuffle away, and then they ask:
Why do people in Australia not fall off?
and then you buy them an ice-cream to keep them quiet for a while.
Personally I loved when my kids asked these questions, as it made me think deeper about I things took for granted, and I started to develop an eye for looking into things without taking them for granted.
In research and innovation, we must always keep asking ourselves some simple questions, as we often just take things for granted.
So let’s looking at one of the fundamental things in computing …
Why do we use bytes?
Is there something about it that makes it special? Is this the perfect size of a processing element, and its discovery was part of the fabric of the universe or did some guy just say:
How many holes can I fit onto my punch tape, without it breaking?
Bits, nibbles and bytes
We take it for granted that we use 8-bits at a time when we process things — a byte — but why not a nibble (4-bits) or even 10 bits? In fact 10 bits would work in that it is nearly 1,000 (1,024).
Well we live in an analogue world where things have a range, but where computational machines only really understand 1’s and 0’s. There are a range of machines that are called analogue computers, but these are too cumbersome and imprecise, so we use digital machines which understand ON or OFF, or 1 and 0. Unfortunately we find it difficult to communicate in binary, so we need to find a better way to communicate with them, and we thus need to code our numbers and characters in a way that computers can understand.
As we’ll see the basics of our current computer architectures are really just based on old teletype computers and on serial communications.
5-bits?
Well the coding of characters into something that a machine can understand has been around since the 16th century when Francis Bacon created the Bacon cipher, and which used 5 binary digits (using an ‘A’ and a ‘B”) to represent the 26 letters for the alphabet:
a AAAAA g AABBA n ABBAA t BAABA
b AAAAB h AABBB o ABBAB u-v BAABB
c AAABA i-j ABAAA p ABBBA w BABAA
d AAABB k ABAAB q ABBBB x BABAB
e AABAA l ABABA r BAAAA y BABBA
f AABAB m ABABB s BAAAB z BABBB
So “Bulgaria” becomes:
AAAAB BAABB ABABA AABBA AAAAA BAAAA ABAAA AAAAA
http://asecuritysite.com/coding/bacon
Unfortunately his codes were not really machine ready. So it was Baudot who created the first usable code in 1870, and which used 5 bits to represent characters. The codes were:

http://asecuritysite.com/coding/baudot
When his codes were used for communications, a start and a stop bit were added to give 7 bits. His legacy still exists in standards such as RS-232, where we define the Baud rate, and which measures the number of characters sent per second.
With many of the original computers the communication links were based on RS-232 and had serial communications, using a transmit and a receive line. The speed of the remote device and the receiving device then had to be synchonised by setting the Baud rate. Typical rates were 300, 1200, 2400, 4800, and 9600, where 300 Baud defined 300 characters per second (or 3,000 bits per second — where each character was typically sent with 10 bits — a start bit, a stop bit, a 7-bit ASCII character and one bit for parity).
The start bit define the start of the communications, and then the 7-bit character was sent, followed by a parity bit which was used for simple error detection. It either used odd parity, even parity or no parity. With odd parity, a parity bit is added to make the number of 1’s in the transmitted character an odd number. This detected an error when there was one, three, five or seven bits in error, but could not detect two, four and six bits in error (as the parity check would seem correct).
But what about lower case and other characters?
While five bits was enough to cover the upper case letters, it gave no scope for upper and lower case, so there was an advancement to 6-bit processing, where the letters could be added without a shift code.
The final solution came with a 7-bit ASCII definition and which has since been used as a base for newer character sets. With the addition of a parity it became eight bits, and the die was cast. Computers thus had to process 8-bits at a time in order to read, store and write characters:
http://asecuritysite.com/coding/asc
A small trick is to remember some important characters:
7 (07 hex) - Tab
10 (0A hex) - Line Feed (/r)
13 (0D hex) - Carriage Return (/n)
32 (20 hex) - A space
65 (41 hex) - An 'A'
97 (61 hex) - An 'a'
The binary pattern between upper and lower case letters only varies by one bit:
0010 0001 ‘A’
0110 0001 ‘a’
So by remembering ‘A’ and ‘a’, you can derive the rest of the letters:
http://asecuritysite.com/coding/ascii
What about the hidden characters?
Apart from the normal alphabet characters, there are a whole lot of other characters that are used to perform other duties. These include the vertical TAB space (TAB — 09 hex), Line Feed (LF — 0A hex), Carriage Return (CR — 0D hex), and Space (20 hex). And just say we want to ring the bell on the computer there’s a character to that: (07 hex).
The vertical tab space (or TAB — derived from Tabular as it could align text into tables) was obviously important to intend text, moving in 5 or 6 characters, and also in programming languages such as FORTRAN which required a TAB space before a line of code. In C coding the TAB space has gained the character representation of ‘\t’. In source code, the TAB character has always been used to indent code, in order for functional elements to line-up, and Python has formally adopted the concept of indentation for defining structure.
Two characters that cause a great deal of problems are:
10 (0A hex) - Line Feed (\r)
13 (0D hex) - Carriage Return (\n)
On the old typewriters, a line feed would move the line down one, and carriage return would move the current position to the start of the line.
There used to be great confusion between different systems on newlines, where Unix system used just a single character (Line Feed) while Windows systems use both a Line Feed and a Carriage Return. You will still see the problem when you copy and paste from one system to another, and where you lose the line breaks.
In the following we can see two line breaks after the “hello world” text (0D and 0A):
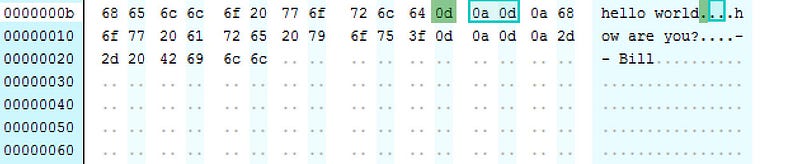
You should also see that a space character is 20 hex.
And what about Greek letters?
After this we moved to 16-bit, 32-bit and 64-bit processing, and which are largely based on the original IBM PC. Soon we developed Extended ASCII, and which used the full eight bits, but again that was not enough for the range of characters to cover all the other symbols and maths characters that we might use.
The solution came in the form of UTF-16, which now used 16 bits for each character, but used the same lower eight bits that ASCII used (and added zeros for the additional byte for the standard characters):
http://asecuritysite.com/coding/asc2
So in UTF-16, we get (where the least significant byte is the same as ASCII):
0000 0000 0010 0001 ‘A’
0000 0000 0110 0001 ‘a’
When searching in content, it is often important to understand that characters can be stored in UTF-16 format, so that a search for ‘AA’ will be:
0000 0000 0010 0001 0000 0000 0010 0001
and not the binary equivalent of:
‘AA’
What about Indians?
So, okay we are fixed on 8-bits as a standard processing size, and we put them in memory with their own address. Numeric values will not fit in with this, as they will often use a larger number of bits such as 16-bits (0 to 65,635), 32-bits (0 to 4,294,967,295). and so on. So how are we going to store them? Do we put the least significant byte in the first location or the last? Is there a magic rule in the university that forces us to go one way or the other?
This, in fact, was one of the great problems in the Computing industry, in that there was no standard for this. The PC used Little Endian, where the least significant byte is stored in the last position, and Big Endian stored the most significant byte at the end. Computers, such as IBM mainframes and Apple Mac, used Big Endian (based on the Motorola architecture), and the IBM PC used Little Endian (based on the Intel architecture). No method is better that the other, but the Intel architecture one by the power of the IBM PC, and even Apple jumped horses in favour of Little Endian.
So for a number 0100 0000 1011 1110, in Little Endian it is stored as:
Mem Location Contents
0 0000 0000
1 0010 0001
whereas in Big Endian in will be:
Mem Location Contents
0 0010 0001
1 0000 0000
This caused a great deal of problems when converting values from one type of computer architecture to another, and was one of the most common forms of computer crashes.
Conclusions
There you go … you took something for granted, but there’s a bit of a history there. As for the sky being blue? Ask a physicist!
I think fundamentally people who innovate look at things like a child does, and it is the ability to question things which is at the core of their skills. They have managed to overcome all the teachers who have taught them that the only way to do things is by methods and techniques, and that knowledge cannot be questioned.
There’s an inner child in us all … try questioning simple things, and you will find that your child will become alive, and your creative side will take over. Forget what the teachers told you, and sometimes question the simplest of assumptions — as our ability to ask simple questions has been beaten out of us by people saying “That’s a silly question!” … and we don’t ask them again.