The True Foundation of our Modern Digital World is … Electrical Power
The True Foundation of our Modern Digital World is … Electrical Power
Should we have ratings of critical infrastructure protection?
As we become more dependent on our critical infrastructure for our modern world, we must make sure it is robust against attack and failure. The core risk is around electrical power supplies. If these are tripped, the whole infrastructure can collapse like dominoes. This is especially relevant as we move to the Cloud, as a power failure in another part of the world can lead to significant problems in other countries.
While many information systems could run for several hours, or perhaps a day or two, a large scale power outage in one part of the world, could bring the whole of your data infrastructure down in an instance, and take days, weeks or even months to recover it.
No power … no data
In 2017, Capita’s systems were knocked out for at least two days, and affected council and NHS infrastructures around the UK (including Sheffield City Council). It related to a power failure in West Malling where generators failed, and shut down the whole of the data centre. Capita is the largest IT provider public sector in the UK, with around a 50% per cent of the overall market (£1.9bn in 2016).
On 8 July 2015, all the flights for UA (United Airlines) were grounded, followed by a computer crash on the NYSE (New York Stock Exchange); and then the Wall Street Journal site crashed. With a major outage on the Internet or a large-scale cyber-attack, these were the kind of things that would signal the start of a major problem. Wired classified it as “Cyber Armageddon”, and Macfee have since pointed towards it being suspicious that it all happened on the same day and that there could have been a major cyber attack.
No matter if it was a cyber attack or not, it does show:
how dependent that our world is on information technology, and a failure in any part of it could be devastating to both the economy and our lives.
Overall the NYSE was down for over three hours and it was reported that it was a technical glitch (costing around $400million in trades). The think that it highlighted is that airlines and the stock exchange are two key parts of our critical infrastructure, and problems in either of these, on a long-term basis, could have a devastating effect. Unfortunately few designers of systems take into account failover systems, as it can considerably increase the costs. Imagine you are quoting for an IT contract, and you say:
“Well that’ll be a million to build, but we’ll need another million to build it somewhere else and then there’s the systems to flip them over, and then there’s the load balancers … and then … hello … are you still there?
Often terrorists and a cyber attack are used as the threat actors in triggering this chaos, but in most cases it will be: a lack of thought; a lack of investment; and/or human error, which will be the likely causes, and these things should not be forgotten. While, in the UK, the banks have been toughening their infrastructure against attack, the whole back-end infrastructure needs examined, especially in the security of power sources, which will bring everyone down.
There are still two major things that most systems are not resilient against:
- Long-term power failure.
- Sustained DDoS (Distributed Denial of Service).
In the UK, especially, our private sector has seen significant funding in creating secure and robust infrastructures, but a lack of funding in the public sector, along with single vendors controlling key elements of it, shows that there may be cracks in the system.
A rating system for critical infrastructure providers?
In the UK, with the banks going through a penetration test from the Bank of England (with CBEST), should other companies and public sector agencies go through the same thing? Could we have a star system for our network and power supply providers, so that we can assess how they would cope with a major outage? Just now, we purchase the cheapest, and just hope for the best!
A 5-star company, would have provable methods of providing alternative supplies, and support 24x7 support for any failures. They would also provide on-site supplies, along with assessing key risks within the environment. Also they would be open for audits of their systems at any time, and also provide audit and risk assessment facilities to their customers. They would also have a strong understanding of the costs to the business for a range of things, such as loss of business and brand damage.
Does anyone really understand failover?
We build systems and we make them work. We know they are not perfect, as they are built with interlinking dependences. If often use risk models to understand where the most likely breakpoints will be, and then create failover routes for these. Two fundamentals ones are often:
No Power and No Network
so will build-in alternative supplies, such as using different supplies from providers, or have a wireless failover system. Then, there’s denial-of-service, where there is an exhaustion of services within the infrastructure, so we build in load balancers and spin-up new instances to cope, but, eventually, these defence mechanisms will exhaust themselves too.
Overall organisations fit into a complex web of dependent services, which are also interconnected, and where a failure in any part of the infrastructure will cause problems (Figure 1).
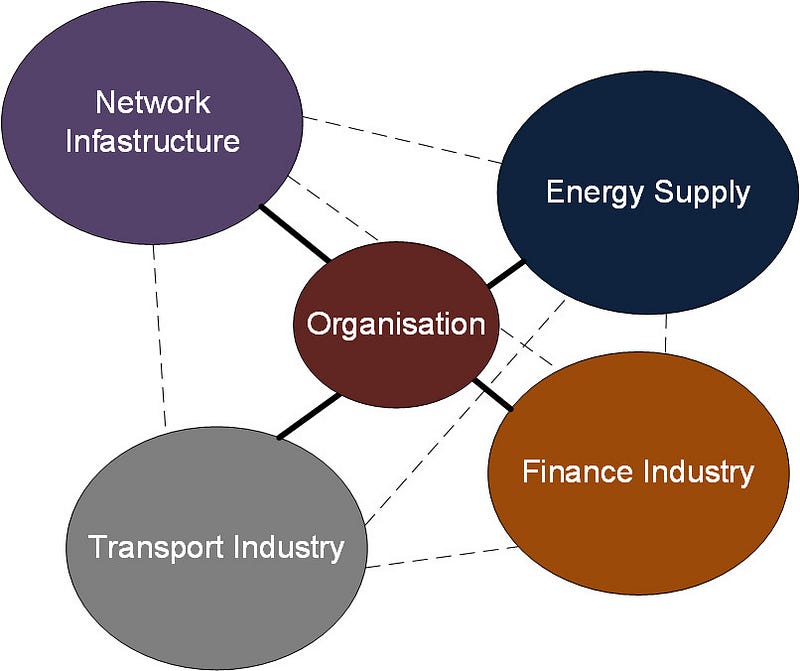
Figure 1: The interconnected world
Failover over failover over failover
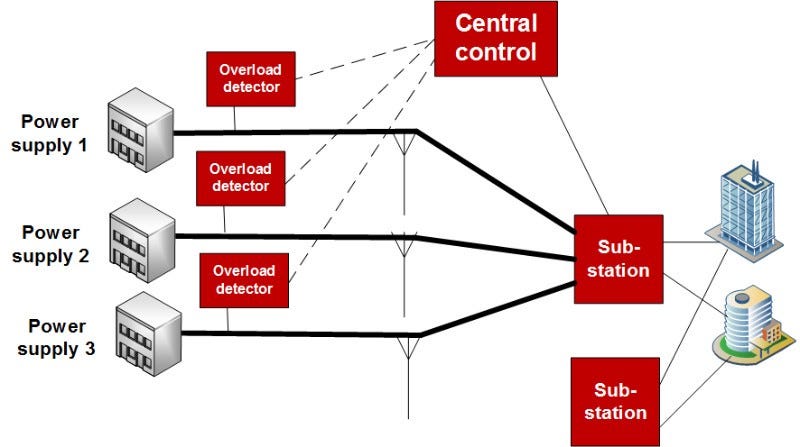
The electrical supply is one of the key elements that will cause massive disruption to IT infrastructures, so the supply grid will try to provide alternative routes for the power when there is an outage on any part of it. In Figure 2, we can see that any one of the power supplies can fail, or any one of the transmission lines, or any one of the substations, and there will still be a route for the power. The infrastructure must thus be safe, so there are detectors which detect when the system is overloaded, and will automatically switch off the transmission of the power when it reaches an overload situation.
For example, a circuit breaker in your home can detect when there is too much current being drawn and will disconnect the power before any damage is done. The “mechanical” device — the fuse is a secondary fail-safe, but if both fail, you’ll have a melted wire to replace, as cables heat up as they pass more current (power is current squared times resistance). If the cable gets too hot it will melt.
In Figure 2, the overload detector will send information back to the central controller, and operators can normally make a judgement on whether a transmission route is going to fail, and make plans for other routes. If it happens too quickly, or if an alarm goes un-noticed, transmission routes can then fail, which can increase the requirements from the other routes, and which can cause them to fail, so the whole thing fails like a row of dominoes.

Figure 2: Failover of power supplies
Large-scale power outage
So, in the US, the former Secretary of Defense William Cohen sent a cold sweat down many leader’s backs, including industry leaders, as a major outage on the power grid, would cause large-scale economic and social damage. At the core is the limited ability to run for short periods of time with UPS (uninterruptible power supply), and then on generators, in order to keep networked equipment and servers running, but a major outage would affect the core infrastructure, which often does not have the robustness of corporate systems. His feelings are that an outage on the grid would cause chaos and civil unrest throughout the country.
Alarm bells have been ringing for a while with Janet Napolitano, former Department of Homeland Security Secretary, outlined that a cyber attack on the power grid focused on “when,” not “if.” and where Dr. Peter Vincent Pry (Former senior CIA analyst defining that the US was unprepared for an attack on its electrical supply network and that it could:
take the lives of every nine out of ten Americans in the process.
The damage that a devastating EMP (Electromagnetic Pulse), such as from a nuclear explosion, has been well known, but many now think it is the complex nature of the interconnected components of the network and their control system infrastructure (typically known as SCADA — supervisory control and data acquisition) could be the major risk.
Perhaps a pointer to the problems that an outage cause is the Northeast blackout on 14 August 2003, which affect 10 million people in Ontario and 45 million people in eight US states. It was caused by a software bug in an alarm system in a control room in Ohio. With this, some foliage touched one of the supply lines, which caused an overload of them. The bug stopped the alarm from being displayed in the control, and where the operators would have re-distributed the power from other supplies. In the end the power systems overloaded and started to trip, and caused a domino effect for the rest of the connected network. Overall it took two days to restore all of the power to consumers.
As the world becomes increasingly dependent on the Internet, we have created robustness in the ways that the devices connect to each other, and the multiple routes that packets can take. But basically no electrical power will often disable the core routing functionality.
Control systems — the weakest link
As we move into an Information Age we becoming increasing dependent on data for the control of our infrastructures, which leaves them open to attackers. Often critical infrastructure is obvious, such as the energy supplies for data centers, but it is often the ones which are the least obvious that are the most open to attack. This could be for an air conditioning system in a data centre, where a failure can cause the equipment to virtually melt (especially tape drives) or in the control of traffic around a city. As we move towards using data to control and optimize our lives we become more dependence on it.
Normally in safety critical systems there is a failsafe control mechanism, which is an out-of-band control system which makes sure that the system does not operate outside its safe working. In a control plant, this might be a vibration sensor on a pump, where, if it is run too fast, it will be detected, and the control system will place the overall system into a safe mode. For traffic lights, there is normally a vision capture of the state of the lights, and this is fed back to a failsafe system, that is able to detect when the lights are incorrect. if someone gets access to the failsafe system, the can thus overrule safety, and compromise the system. This article outlines a case where this occurred, and some of the lessons that can be learnt from it.
The damage that a devastating EMP (Electromagnetic Pulse), such as from a nuclear explosion, has been well known, but many now think it is the complex nature of the interconnected components of the network and their control system infrastructure (typically known as SCADA — supervisory control and data acquisition) could be the major risk.
As the world becomes increasingly dependent on the Internet, we have created robustness in the ways that the devices connect to each other, and the multiple routes that packets can take. But basically no electrical power will often disable the core routing functionality.
Estonia thinking ahead
Just imagine if you woke up, and there had been a massive cyber attack on your country by a large nation state, and, within hours, all of the major governmental systems have been hacked, and the Internet infrastructure failed. For this the data used by your government could been destroyed. So, if your country has been progressive in its adoption of electronic services, the government would have no health care records, no birth certificates, no social care records, … all of it would be gone!
The threat of cyber warfare is real, and it is a threat which is increasing. Small nations, especially, are particularly afraid of an attack from larger ones, especially where there is control of key critical infrastructure, such as the power network, and in the face of a massive denial of service attack.
Previously, in 2009, Estonia was hit by a suspected cyber attack from another nation state, and has now decided to proactively look at moving copies of its data to the UK, for protection. Currently they have been using data stores in their own embassies around the world to mirror their core governmental data, but this is the first move to formalise the storage of it outside the country.
The data stored will include information related to their citizens, such as for birth records, and also government documents. For them the UK is seen as a relatively safe place against attack, with a proactive approach to data protection. Previously it was attack in 2009, and which took out their infrastructure for several days.
Overall Estonia has embraced the Internet like few others, and have managed to put most of their government services on-line. This includes voting, paying taxes, and virtually everything else.
How would a country cope with initial phases of a Cyber Attack?
Perhaps the recent coup in Turkey gives a hint on the type of scenario that we would see on a Cyber attack, and where internal control of the network would cause a disruption in service provision.
In the US, Senator Joe Lieberman (I-CT) wrote a bill named “Protecting Cyberspace as a National Asset Act of 2010”, and which was seen as the “Kill switch bill”, where the President would have the power to take over parts of the Internet.
For this, as with many finance companies, countries need to invest in their 24x7 SOC (Security Operations Center) for critical infrastructure and which monitors the complete network and data infrastructure, and which can control and manage a potential attack:

On an attack it is likely that the Security Operations Center could take control of the internal network, and limit access to services. Five initial stages could be:
- Stage 1: take-over. So the first thing that the network and security engineers will have to do on a cyberware attack will thus be to take-over the control of the traffic, otherwise its own citizens will crash the internal infrastructure. The challenge in this phase is to control the internal forces, while dealing with external pressures. In these days, many of the services use Cloud systems, so throttling back on external traffic could also disrupt the network.
- Stage 2: Coping with the threat. As Stage 1 happens, security analysts are likely to be analysing the external threats, such as coping with a large-scale Distributed Denial of Service, and try and understand how they could cope with an external (or internal attack), without actually affecting the internal network. The plans would then have to be carefully intertwined to make sure that any control on the external threat does not affect the internal operation of the infrastructure. A large-scale crash would be almost impossible to cope with, as servers and service normally interconnection, and where the infrastructure would take a while to recreate itself. Like it or not, much of the infrastructure still requires a great deal of human intervention.
- Stage 3: Observation and large-scale control. At this stage we will see the Chernobyl Nuclear Power Plant effect where the most important alarm on the system was swamped by other less important ones. So at this stage alerts will be coming in on system crashes and problems, and thus plans will be in-place to filter these alerts so that only the most important ones will be fed to analysts, and who can then try and put in-place plans to overcome the problems before the infrastructure collapses. While many have tried to model the complex behavior of our network infrastructure, it is almost impossible to predict, so security and network analysts will have to cope with the large-scale disruption, and make decisions on how to keep the core infrastructure up-and-running. A key focus of this stage would be to make sure that military, transport, energy, health and law enforcement systems were given the highest priority, along with financial systems (as the shock wave of a disruption to the economic infrastructure of the country could be long lasting)
- Stage 4: Observation and fine-control. At this stage, we would move to a point that there was some stability, and where lesser alerts could be coped with. This might relate to services which were less important, but which need to be sustained. A key focus would be to protect the financial and commercial interests of the country.
- Stage 5: Coping and restoring. The final stage is likely to be the restoring of normality, and try to recover the systems, and which may be damaged in some way. On a cyber warfare event, this could be an extremely costly process, especially if the country has not coped well with the attack.
A failure to cope with the initial attack could make it extremely difficult to take control of the situation and also to recover from it.
Conclusions
With all our complex infrastructures, it is the most simple of things that can trip them all, and cause large-scale chaos … the electrical supply. Unfortunately it’s not an easy call to make as the systems need to be safe, but this safety can lead to automated trips and are in danger from operator error.
As we move into a world, too, where the intercommunication of signals between cars and the roadway, and between cars, it is important that we understand if there are security problems, as with flick of a switch an attacker could cause mass chaos.
I think that very few companies and organisations have plans for a major disaster, and how their business and staff would cope with a major outage of either power or network provision. In a military environment, the two focal points to disable the enemy is to take their power away — bomb the power plants — and take-out the communications network. These two things effective disable the enemy, and in a modern business infrastructure, based on information processing and analysis, it is electrical power and network connectivity that are the most critical.
In conclusion, we are becoming an extremely small world, and where we are all inter-connected and inter-linked in some way, so we need to understand our links, and perhaps look more at our infrastructure rather than always on our front-end systems.