Facial Recognition: You Cannot Hide From The Machine

Facial Recognition: You Cannot Hide From The Machine
The Rise of AI: Good or Bad?
Introduction
Image recognition has been researched for decades, and, generally, we have moved from hand-crafted image classifiers towards deep learning. Generally, computer systems have moved from being fast to analyse and score possible solutions — such as in chess — to learning the key classifiers that we use to visualise our world. This progress was highlighted in 2015, when the best deep learning method at the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) finally surpassed that of a human.
As humans, we normally recognise each other from faces. Our brains thus have a core ability to quickly make sense of a face, and abstract out key features. Someone’s height, their voice, their clothes, their gate, and even their smell might also help us with identifying a person, but at the core of our recognition of other people is their face. Their face is their brand, and our brain is able to store abstract representations of faces and keep these for instant recall. A major challenge with facial recognition is that a face may be at different angles to our eyesight and have different lighting, and our brains must thus remap into a simpler model of the face. To store many different images of someone’s face would be too costly in terms of storage, and would not have a great success rate for matching against the pixels in an image. Thus we extract out the key features of a face and then can match against that.
While facial recognition has been around for many years, it is only recently that it has become mainstream such as within mobile device authentication and in image recognition within video and image analysis. Our faces, though, will change over time, but some features such as the length of our nose will vary less than our hairstyle. The challenge for a cognitive engine is to still recognise a face, even with a different hairstyle, or with or without a beard.
The human brain is thus able to abstract faces from key features, even when many of the features are different from the remembered version of the face. We can still recognise a friend instantly, even if they have grown a beard and cut their hair. This, though, is a challenge for a computer, as it needs to normalise faces to its stored model, and then determine the errors between the current face and the face it has stored. For automated login systems, such as for smartphones, the time that the device has to make a decision, is often less than a second, otherwise, the user will lose trust in the recognition method.
The key elements of biometrics are:
- Universality. This defines that the method will be available for most users.
- Uniqueness. This defines that the method must be unique across the population.
- Permanence. This defines that the method does not vary over time.
- Collectability. This defines the ease of which the information can be gathered.
- Performance. This relates to how accurate the method is for a range of situations.
- Acceptability. This defines how acceptable the method is to a user.
- Circumvention. This defines how easy it is to trick the system.
https://www.youtube.com/watch?v=W15cg52mJ9A
Behavioural biometrics
Face recognition is a type of physiological biometrics and which is based on a person’s physical characteristics that remain fairly unchanged over time. These include things like fingerprints, iris/retina, and hand/palm recognition. Normally, though, our faces are the most exposed biometric and which can be scanned remotely, and with or without our consent. If you don’t want your photograph to be taken, you might place your hand in front of your face, but in public spaces, your face may be scanned without your permission. The active probing for a fingerprint scan, though, often involves your physically consenting to apply your finger to a scanner. You might also wear glasses on your face, or hide your face in a hoodie, in order to evade face scanners in a public space. But, increasingly, we are using our faces as ways to log into devices, and identify ourselves are airports, and also make payments.
Within any biometric system, we identify success rates with true-positives (the guess was correct), and false-positives (the guess identified the wrong person). This then defines the error rate, and the higher the error rate, the lower that user confidence is likely to be. Fingerprint recognition often achieves rates of better than 3%, and uses patterns within the finger (such as arch, loop, and whorl) and minutia features (such as ridge ending, bifurcation, and short ridge). Face recognition in smartphones now has rates which can match fingers, as it uses many features of the face, and can learn these over time.
What is in a face?
Our faces often define us to others. While a voice is important in identifying us to others, it is often our faces which are used to quickly identify a person. This has been important in our evolution as a species as we need to quickly identify our family, our friends, and, especially, our enemies. In almost an instant, our brain can scan a room, and quickly identify those people we know, and those we don’t. It identifies friends and enemies. It identifies those we are attracted too and those we are not. It makes judgements on genders. It analyses emotions. It can tell who is happy, and who is not. Computer systems now have the challenge to equal this amazing feat, and it is generally not easy. But, as they evolve, it is likely that we may feel increasingly uneasy about their ability to spot us, and trace our faces to other traces of activity. So while we may defeat fraud with better facial recognition, there is the ability of CCTV cameras around a city to trace our every move.
The key features of a face that we can gather:
- Traditional features. This includes the size and shape of eyes, nose, cheekbones, and jaw.
- Three-dimensional mapping. This includes a 3D mapping of the face in order to determine its general shape.
- Skin texture. This defines the distinctive elements of the skin, such as lines, patterns, and spots apparent. This type of analysis is often used in age determination, as age lines change our face over time.
In terms of an evaluation we can define a target user and an imposter and legitimate users. A biometric system which allows imposter to impersonate a legitimate user is obviously a security risk, while a biometric system which identifies a target user as a legitimate user is likely to reduce user trust. The main evaluation methods are then:
- False acceptance rate (FAR). This defines the percentage of times that the system accepts an imposter as the targeted user.
- False rejection rate (FRR). This defines the percentage of times that it identifies a target user as an imposter.
- Receiver operating characteristic (ROC). This illustrates the trade-off between the FAR and the FRR.
- Equal error rate (EER). This defines the point where the percentage of false acceptances is equal to the percentage of false rejections. Within a ROC curve we can find this at the point at which they cross-over, and we aim at a low value of EER as possible.
- Authentication accuracy. This defines the percentage of identifying a user correctly against both imposters and legitimate users.
Analysing a face with a cognitive engine
The ability of a computer system to match a face often involves scanning a 2D image which has one or more faces. Once they are identified within a rectangular area — as faces have a characteristic rectangular shape — the requirement is then to locate the key characteristics which vary across different people. This includes finding a face through an abstracted model of what a face should look like.
In Figure 1 we see a face can be split into key distinguishing features which identify the brows, eyes, nose, and mouth. In order to simplify things we can then represent the brows with a start and an endpoint, the eyes as a start and end, and points around the turning point of the top and bottom of the eye, the nose by top and bottom and points in between, and the mouth as a start and end point, and two points in the middle. In the end, we can then make measurements around the facial landmarks, and also between them.

We can use the Microsoft Cognitive Engine and can run the code given in the Appendix. This will return the landmarks and try and make sense of the face. If we take an image of the Barack Obama we see that it has detected the face and the key facial landmarks and within a bounding box:
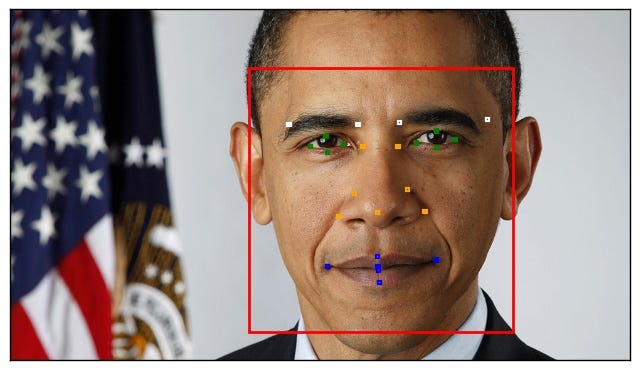
The result comes back as a JSON object, and which defines the key face landmarks. It identifies the face within a face rectangle, with markers for the brows, eyes, nose, and lips (Figure 3). We can also see other things returned which identify other key features of the face, including hair colour, emotion, whether wearing glasses, the pitch, roll and way, and even an estimate of the age and gender of the person.

Detecting faces
The key part of detecting a face and areas of interest within an image is normally achieved with object detection. This is often achieved with Haar feature-based cascade classifiers, and is an object detection method was proposed by Paul Viola and Michael Jones. Overall it is a machine learning-based approach where the system is trained with many positive and negative images.
So let’s take an example of detecting faces. In order to train the classifier, the algorithm requires a good deal of positive images of faces and negative images without faces. The system then extracts features from these using the grey scale version of the image. Each feature becomes a single value determined by subtracting the sum of pixels under the white rectangle from the sum of pixels under the black rectangle:

We thus classify into: edge features; line features; and four-square features. David Cameron’s hairline looks very much like an edge feature, while his mouth is more like a line feature. To find features we analyse the changes in the images, such as from dark to light. For eyes we see that the eyes are often darker than the bridge of the nose, so we can look for dark -> light -> dark:

and so when we run the classifier, we get:

where you can see it has detected David Cameron’s face and eyes, but it seems to think that we have an eye in his mouth (and ear). If we apply a cat’s face, the detection is poor as it will try to detect human faces:

but there are a whole lot of filters which can be used, including a cat face detector. So when we use this, the cat’s face is detected:

And finally, we can try and detect a smile. For this, we add the XML training data, and then try and detect an aspect ratio that represents a mouth (long and thin) and with a minimum size:
smile = smile_cascade.detectMultiScale( roi_gray, scaleFactor= 1.7, minNeighbors=22, minSize=(25, 25) )
The following outlines the Python code used:
import numpy as np
import cv2
import matplotlib.pyplot as plot
import sys
imfile = 'http://img.sxsw.com/2015/films/F52361.jpg'
imfile = 'F52361.jpg'
file='111.jpg'
if (len(sys.argv)>1):
imfile=str(sys.argv[1])
if (len(sys.argv)>2):
file=str(sys.argv[2])
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')img = cv2.imread( imfile)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
file1 = "filename"
cv2.imwrite(file1,img)
and the smile part is:
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
smile_cascade = cv2.CascadeClassifier('smile.xml')img = cv2.imread( imfile)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
smile = smile_cascade.detectMultiScale(
roi_gray,
scaleFactor= 1.7,
minNeighbors=22,
minSize=(25, 25)
)
for (ex,ey,ew,eh) in smile:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,0,255),2)
Demo: https://asecuritysite.com/comms/face
Pitch, yaw and roll
We might have a standardized model of the face for a person, which involves measures of the facial features for an image which is looking directly at the camera. For the actual position of the head with respect to the viewer, we measure the pitch, roll, and yaw of the face, with respect to the viewer. The pitch relates to the up and down movement of the face (someone nodding their head), the yaw to the left and right movement of the face (someone shaking their head), the pitch to the clockwise or counter-clockwise movement of the face (someone rolling their head). For a perfect model, we have an angle of zero degrees for all three measurements, and will then aim to measure the pitch, roll, and yaw of the face, and covert the actual measurements into a normalised model. This measure thus covers the face into a standard model, and where we can measure error values to determine the best match.
For example, if the width of the mouth is measured at W, and the face is at a 45-degree angle to the camera, then the actual length of the mouth is W/cos(45°), as illustrated in Figure 9. Basically, though, we have three-dimensions, this if we measure the angle for pitch as (_y), for yaw (_x) and roll (_z), the conversion is then:
Width = √[(W/cos(_x)² )+ (W/cos(_y))² + (W/cos(_z))²]

Emotion, hair and other features
While the landmark features on a face are the core element of any analysis, we also recognise people from their gender, whether they wear glasses, have make-up on, and their hairstyles. While gender is less likely to change over time, facial hair can often change the look of a face on a daily basis. The additional results from Barack Obama’s face are then shown in Figure 10.
Link: https://asecuritysite.com/comms/faceapi

In this case, we see that he had hints of a moustache (0.1), a beard (0.1) and sideburns (0.1), but no glasses or make-up have been detected. For hair, we see confidence metrics on baldness, hair colour (black, gray, brown, blond, red or other). But it is in the deeper analysis of age, gender and emotion that we see a deeper degree of machine learning in the analysis. In this case, the cognitive engine has determined his gender correctly (male) and has a good guess at the age of at the time of the photograph (54). It has then detected his emotions within the photograph. These include an attribute for the smile (0.371), and for the emotions of anger, contempt, disgust, feature, happiness, neutral, sadness and surprise. Overall these were defined by the facial action coding system (FACS) [1], and which includes 44 Action Units (AUs) to describe facial changes. For a smile, we have a Cheek Raiser (AU 6) and Lip Corner Puller (AU12).

In many applications of AI, the detection of a smile can be important. This might relate the detection of patient happiness or in positive effects on watching a movie. Normally smile detection is seen as a binary classification, where someone has a smile or not. In many cases, SVM and AdaBoost work well in binary classification problems, and has been used extensively within smile detection, but can sometimes struggle to produce a result in real-time. Overall, Extreme Learning Machine (ELM) has produced good results with a low costing in computation.
There are two main methods that involve either a geometric-based approach or an appearance-based approach. With the geometric approach, we look at deformation within the facial geometry, such as:
- The percentage of teeth shown as related to the size of the mouth.
- The normalized, average minor/major axis diameter of eyes.
- The upper/lower lip curvature.
- A check on whether there is a cheek fold. This is an effect where the line around the nose connects with the check.
- A check on whether the forehead has wrinkles, as this can identify anger, and where the brows will be lowered.
- The vertical distance from inner tear duct to the eyebrow.
For appearance-based approaches, we look at the dynamics of the facial features, and thus involves a time-based method.
Weaknesses of facial recognition
There has been a wide range of attacks on facial recognition systems. This includes using photographs and video playback to trick the processing system, especially when used in certain lighting situations and for given viewpoints. Our face, too, is not quite a unique as a fingerprint scan, and where we can have people with similar faces. Even Apple’s Face ID system has been shown to struggle when faced with two similar faces. While accuracy is increasing, there are still face positives, and while face recognition for the tracking of consumer choices might not need high success rates, in areas such as border control and terrorism-related areas, it is important to have high accuracy, and also human checking.
In many applications, though, machine learning is used to perform an initial filter of “faces of interest”, and then when can be checked by a human operator. A world where computers could recognise faces with a high success rate, and then match to other data, might be a world that would be unacceptable for many people.
While deep learning methods have been successful in improving face recognition, there is a worry that many of the faces that are being used for the classification are typically from white people. Success rates can thus be poorer for those from other ethnic backgrounds.
A core worry in many deep learning methods for facial recognition is that it is difficult to know how the algorithm has come to its findings, especially when it is fed with bad data. In the UK, it was found, for example, that pictures with sand dunes in them were classified as obscene images. The problem can be overcome using guided back-propagation, and where we can understand the key features used in classifying faces. Adversarial methods can also be used against the machine learning method, if the adversary knows how the algorithm is classify, and could mock up images which target key classifiers for positive identification.
Facial recognition for good and bad?
Facial recognition can be used for good and bad purposes. For fraud analysis, a mobile device can quickly determine the person making a transfer, and verify them. The days of just entering your credit card ID and your CVV2 number on their own are quickly passing, and where face scanning is increasingly used as a check. From a human trust point-of-view, this is often seen as a good application, as it is likely to significantly reduce the risk of fraud on someone’s bank account. We can also use it for identifying people in disaster recuse situations, and in people trafficking situations. But there are many other application areas where organisations can match people as they shop and then to their purchases. Every CCTV camera can thus be a spying device, and match faces, either for the routes they take, or to match the routes to a specific person. The technology must, thus, be used responsibly, and consent must always be sought from users. In extreme cases, such as in public safety, though, consent is often not required, but the usage of this type of application could lead to significant breaches of human trust.
Appendix
Here is the associated code:
[1] A P. Ekman and W. Friesen,Facial Action Coding System: A Technique for theMeasurement of Facial Movement. Consulting Psychologists Press, Palo Alto,1978