We Need To Dump Our Role-based Security World!

We Need To Dump Our Role-based Security World!
One of our most successful spin-outs is Symphonic. Why? Because they do something that everyone agrees that is right, but few actually properly implement it. The basis of Symphonic is the integration of context, roles and attributes into the rights to every element of data or service, and then integrate that into a governance engine. For interdomain rights, you define a policy with roles and attributes, and the service that you are connecting to, and the governance engine tells you which role proofs and attributes you need to gather, and which of these are trusted. You then gather these, and the governance engine makes the choice as to whether you can get access to the service. In a Microsoft domain world, you get access because you have proven your role and your ID, and, typically, that it. The whole thing just doesn’t scale, and increasingly is at the core of most security breaches.
Our role-based world?
In our world, we all have roles … a father, a teacher, a GP … it is how we get certain rights. But, just because I am a teacher, doesn’t mean I can automatically teach French. And so I might then have to define the role of a teacher of secondary school French. But then we have all the other subjects. Then, because I am a French teacher in one school, can I teach in other schools, and so it goes on. With a role-based approach, we end up having an almost infinite number of roles of which each has certain rights. The whole thing becomes extremely complex. In our world, though, we add in attributes and context. I am a father, but my context is that I am the father of this person. I am a father, and I live in Edinburgh, and will thus gain rights for this.
In our computer systems, though, we have never really weaned ourselves of our love of role-based security. If you look at your domain rights on our computer in work, you will find you have lots of roles, and that each inherits rights. When creating, it all makes sense, but then we just keep adding people to roles, and we lose sight of how the whole system works. When we looked at the organisational structure, we used to ask for access to the LDAP information, as this gave us a mapping of the whole of the infrastructure, and who had access to what.
Most hacks now involve some form of privilege gaining from role-based security. But why does role-based security even existing in this modern world, where we can integrate some many things into the identification of a person? Well, it is just a historical model operating system world that had a mainframe and connected terminals. I remember the days of “admin”, “staff” and “students”, and then we added “guest”, and from there it has just spiralled until we have little sense of who has access to what. And so most systems have little care if you log in to your computer from Edinburgh or from Moscow.
The right way?
And so I pose this question:
What’s The One Thing That Every Agrees Is Right In Computer Security, But Few Actually Do It?
Well, everyone knows that we should be encrypting data at its core level (or in the application layer), and not relying on tunnels or single encryption keys for our protection. In this way, we can embed encryption into the actual data and then define the actual access rights (and without relying on domain/operating system rights). Few people still trust the security of user names and passwords to properly protect data, but we still blindly use it for our accesses to data.
Why can’t I give access to my daily step count to a cancer research company, but make sure that a tobacco company have no rights to it?
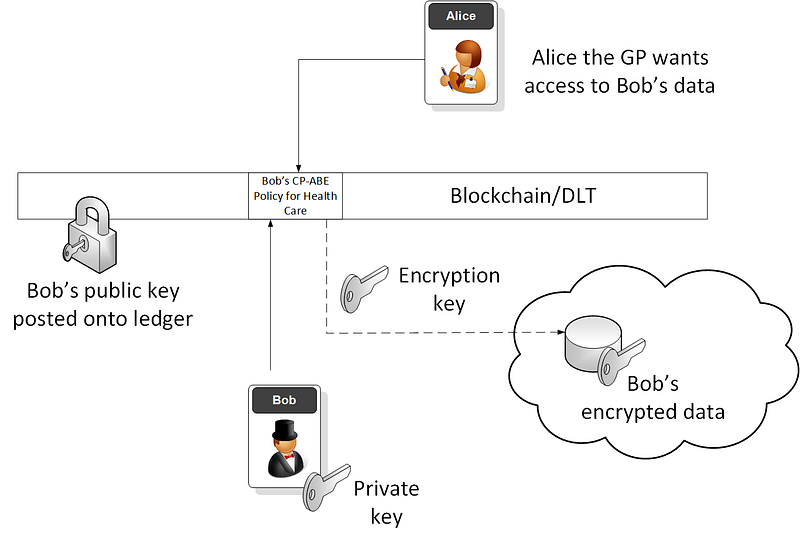
And, so, if Bob the patient wants to give Alice the GP access to his health record, he might provide the right encryption key to open it. But, what if Bob is not on-line for the access? Well, we typically define an access policy, and where we can define the rules for access. This access can then relate to the generation of the required encryption key. It thus doesn’t matter where the encrypted data is stored, as only the required encryption key will open-up the data.
Bob might then give his consent as part of his policy to Alice. Then when the policy is checked, Alice can then have rights to his data. But, at any time, if Bob thinks that Alice is using his data in an inappropriate way (such as selling it to Google), he could take away the consent, and she will not be able to generate the required encryption key. On an emergency, too, if Bob was to have a life-threatening incident, we could add a policy statement that allowed any GP access to his record (but this would be logged, and check after the incident).
And so we need to move to a point where every single data element has some policy applied to it, and where the data is protected. For this we can turn to CP-ABE (Ciphertext Policy — Attributed Based Encryption), and where we bake the policy into the data, and encrypt it so that it cannot be accessed, unless we comply with the policy.
Let’s say we have some modules (csn09112, csn08102 and csn10101) and some roles (staff, admin, student, and root). These will become attributes in the system, so that all our users will gain (or verify) their rights to these attributes. Thus a student who is enrolled on csn09112 will have the attributes of “student” and “csn09112”. A staff member who teaches on “csn09112” and “csn08102” will have the attributes of “staff”, “csn09112”, and “csn08102”.
If we wanted to create a policy of access the marks for a student, we could define any two attributes of “staff”, “csn09112” and “admin” (left-hand side of Figure 1). In the diagram, ∧ is AND, and ∨ is OR. We could also define that “root” was added to the top of the tree (right-hand side of Figure 1). These sample policies would then be:
- “staff csn09112 admin 2of3”. Any two of three attributes are required.
- “staff cns09112 admin 2of3 root 1of2”. Any two from “csn09112”, “admin” and “staff”, or “root”.

Now let’s try to access the CP-ATE data with a policy of “staff csn09112 admin 2of3” and with the attributes of “staff”, “csn09112” and “csn90101” [here]:

And we can see that we can decrypt the encrypted data. But now let’s say we are a student who is studying “csn09112” and “csn09101” [here]:

Now we see we do not have enough attributes to match the policy. And now, we login as “root” and with a policy of “staff csn09112 csn09110 2of3 root 1of2” [here] and we get

So, we can now create a system which can dynamically encrypt data based on a policy. The access to the data will not be controlled by the operating system any more, but is embedded into the data. In this way our data can existing an an open place — such as in the Cloud — and where we have trusted attribute providers.
Conclusions
If we were to start again with our data infrastructure, we certainly wouldn’t start from where we are. Most of the systems we have created — our spreadsheets, word documents, databases, and so on — have little in the way of embedded security, and we must thus overlay our security models. This makes the infrastructure complex and where is becomes difficult to manage. CP-ABE provides a much simpler solution and allows us to make sure our data is properly protected.
CP-ABE is brought to you by the wonder of elliptic curves and crypto-pairing, and does things in the way that things are meant to work in computer security. Within a blockchain world, citizens could store their CP-ABE policy on the blockchain, and define the attribute provides they trust. Any updates to the policy could then be achieved in almost real-time. The data, itself, will not be stored on the blockchain, and will simple contain a link to the encrypted data, and a smart contract would then be responsible for generating the right key for data access.

Here is my simple demo and which uses 256-bit AES encryption to protect the data: