For The Love of Big Data, Threat Schema and Directed Graphs in Cybersecurity

For The Love of Big Data, Threat Schema and Directed Graphs in Cybersecurity
The Rise of Machines and Data in Cybersecurity
The V’s of Big Data
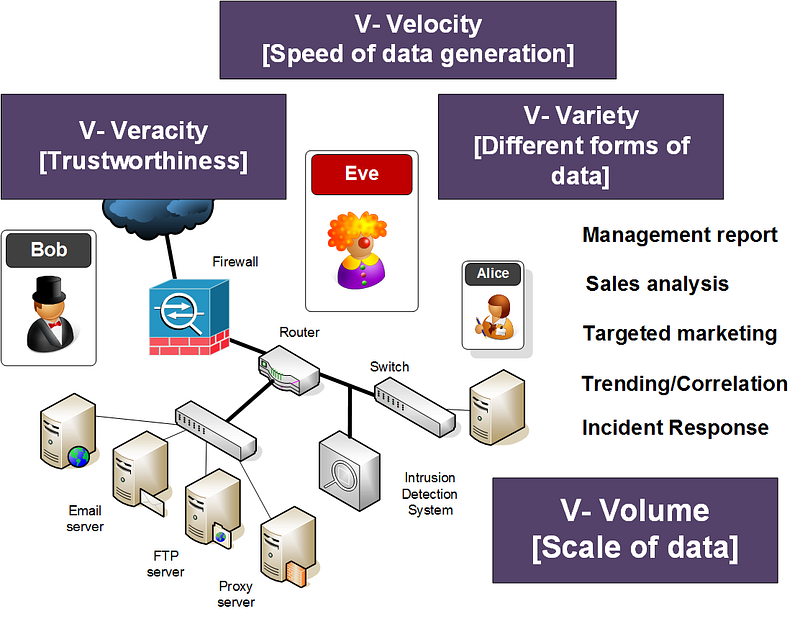
While Big Data is often a difficult term to define, in this article, we will define it as data which is gathered from multiple sources and which is likely to be made up from a wide range of data formats, including for system alerts, unstructured and semi-structured data, and on the data related of cyber events. We commonly define that a key factor in Big Data to be able to cope with the Volume, Veracity, Velocity, and Variety, and thus provide Value (Figure 1). One of the great advantages of creating a SIEM infrastructure, is that the logs gathered can be used for a range of business-focused reports (such as for management reports for traffic flows and downtime), sales analysis (such as from taking the log data gathered from a Web site), targeted marketing (such as understanding the demographics of those using a Web site); trending/correlation (understanding the peak times for sales); and incident response reporting.
Goal-oriented
You can’t really teach someone to do something, without defining what the end goal is.
Machines are generally good at learning single tasks, and where they can complete them within defined limits of operation. They can then learn the steps taken to complete the task, and so we can define the core task for a machine to undertake, and the required data capture and the machine will make decisions either based on logical steps or basedsed on risk-based scoring. A firewall, in itself, can be intelligent in that it can learn the IP addresses which are shown to not be malicious. Over time we can define a white list of IP addresses, and put malicious looking ones onto a blacklist. The scoring of the maliciousness might involve a scorecard of activity, including its involvement in DDoS activity, or with a well-defined signature of being part of a botnet, or even in the detection of a virus. An IP address malicious score could then be dynamically gathered over time, and where a known malicious address could improve its scoring by not being involved in malicious activity, and a good IP address would gain bad marks for suspicious or malicious activity.
A device such as a firewall can thus be defined as a goal-oriented device, and where its goal is achieved through rules. These rules can then be modified over time, and refined, but the overall goal of the firewall is to still provide low levels of latency and high success rates in spotting packets and sessions which do not match the security policy of its host organisation. A firewall, though, can only perform a part of the overall policy, and where other agents on the system will aim to perform other keys parts. This leads us to the concept of agent-based systems, and where each agent has a well-defined role, and where we may have centralised control of the agents. Each of the agents can then act in an autonomously and in a distributed manner. An example of a distributed agent is Snort — and where an IDS agent can be installed on networked devices. These agents are tasked with predefined rules and will focus on analysing network packets for matches against these rules. Once there is a match, the alerts are added into an alert file. We can also use a Syslog agent to send the alerts to a Syslog server, or use a SIEM agent to forward the alert to a centralised storage and processing system.
So while we can define intelligence within goal-oriented devices, we are a long way of defining an integrated sense of purpose within our cybersecurity infrastructure. For this, the whole of the information infrastructure within an organisation would have to act as a complete entity, and where decisions were made based on well-defined rules (as defined by an expert system or a procedural approach), but where data could be quickly recalled and processed, and which could overrule previously defined rules. It would then be possible to update a predefined rule based on new evidence, and where an improved rule could be put in its place. With this, we could define a baseline — or starting point — level, and where the infrastructure would then evolve from this starting state. This would allow the information infrastructure to change itself over time, and create fast-acting rules which evolved to new threats.
For example, we might define a rule that generally blocks SSH accesses on our Cloud infrastructure through a firewall rule, but allow access from an administrative account and on a predefined IP address. But our system could recall information that the trusted administrator also logs in from another IP address, and where a cognitive system could then overrule the blocking of the accesses from the new IP address, based on events in the past. Over time, we could thus evolve the firewall rules to enable accesses from the trusted IP address. But, then, on checking one of the accesses, there is an event which marks the specified IP address as being suspicious, the cognitive system could overrule the newly written rule. This type of process is typically seen as an Intrusion Prevention System (IPS) and will work well for fairly simple types of threats, and with standard signatures (such as with malware and scripted attacks), but will often struggle with anomaly-based threats (such as for fraud and data leakage). An adversary — Eve — could thus determine the way that the cognitive engine was recalling and processing information, and could look to compromise its operation. For example, Eve could find out that the machine has learnt to trust certain source IP addresses from users who have logged-in successful over the past three months, and who have no significant alerts against them. Eve then creates a script to perform successful logins from her attack address and then performs some simple scripted actions. The machine then will learn to trust her IP address and could give Eve’s IP address a higher level of privilege. Once granted, Eve then abuses this privilege to perform an attack on the system.
Towards a cognitive machine?
Within cybersecurity, unfortunately, we are increasingly swamped with alerts from systems, an, in order d to cope with this, we need a more cognitive approach in analysing alerts, and one which matches the operation of the human brain (but can perform its actions so much faster). This type of approach will generally aid decision-making, and not rely on humans making judgments on fairly trivial things. A cognitive engine would thus be able to be (Kelly, 2015):
- Adaptive. This would allow the machine to learn from changes as new goals and requirements evolve. The engine, too, could also cope with unpredictability and ambiguity, and make reasoned decisions. This adaptability would allow pre-defined rules to be changed and migrated over time, and would also support the strengthening of security when there is a perceived attack, and to reduce it when not under attack.
- Interactive. This would support the interaction of the cognitive engine with a whole range of services, people, systems, and so on. A core part of a cognitive engine — as we see in the brain — is the ability for it to take inputs from a range of sources, and then provide outputs in the required way.
- Iterative and stateful. This involves understanding previous interactions and be able to sustain future ones, along with plotting the best course and to learn new routes. As humans, our interactions with others are often stateful, and where we remember where we have left things with different people. Within a cognitive engine, we would thus define our interactions as well-defined states, of which we move into and out of. The probabilities of these moves between states is often a key factor in defining system anomalies. For example, if we have received a TCP SYN flag for a connection, and sent back a data segment with the TCP SYN and ACK flags sets, we will wait in the state to receive a TCP ACK flag from the host. If we receive another TCP ACK flag on the same TCP ports, we can see this as an unlikely state, and flag it as an anomaly. While signatures are often good at identifying machine-based threats, anomaly detection is often used to detect unexpected things.
- Be Contextual. This allows the identification of key contextual elements within the data, including locations, names, dates, and so on. The original data may be in many different formats and could be structured, semi-structured or unstructured.
Machines and Data
For a machine, the core of intelligence is the access to data, and where they can derive the required information, or where it is used to learn the required connections. Within all our actions we must define whether we need to make a decision based on a real-time or non-real-time basis. Within a Distributed Denial-of-Service (DDoS) attack we must cope with the incoming data and respond to the threat with our defence mechanisms — an active defence. To respond we then identify the network traffic which is the source of the attack, and undertake the best form of defence, without affecting the quality of the service for other users. This might involve reconfiguring the firewall with a blacklist of IP addresses, or to spin-up more resources in order to cope with the increased amounts of network traffic, or even to apply a quality of service on the network traffic, so that good traffic is given priority over bad traffic.
Within an organisation we typically deal with semi-structured data, and where we gather from logs from multiple places on the network, such as from hosts, firewalls, IDSs, Active Directory servers, and so on. Each of the hosts will typically be setup with a data gathering agent and then configured to pick up the required events. The greater the number of events defined, the larger the amount of data that needs to be gathered. We thus define the events that are required for threat analysis, and then aggregate these into a single data source (Figure 2). The data is then normalised and parsed and stored in a more structured form, and which can be processed for the identification of standard signatures of attacks, or mined for key search terms.

At this stage, we might reduce the alerts generated from millions into just a few significant ones. We then have to design the system so that we gather enough data events that will give us the required information to cover our threats. Obviously the more we gather, the more data we will have to use within investigations. But, too much data could be expensive both in the costs for data gathering licences, and also in processing/data storage overheads. Each of the systems, too, have a finite amount of space to store logs, thus some of the devices might roll-over their logs once their memory is full, thus we must make sure we gather the data within defined time limits. For many systems, the core of this is a Syslog server, and which is a central place on the network where each of the devices sends their data to. The SIEM infrastructure then just has to gather the data from the Syslog servers, and not go and poll each of the devices.
If we increase the amount of data, the amount of time to search and process, is also likely to increase, thus we crawl over the data and index it for its structure and its linkages. In this way, a graphical interface can simply mine the metadata and associated links. For example, by mining data packets, an IP address may be associated with domain names, TCP ports, and MAC addresses. These data points can then be used within searches, and where their linkages are presented in a directed graph (knowledge graph) and define interesting fields.
Directed Graphs and Cyber-threat infrastructure schema
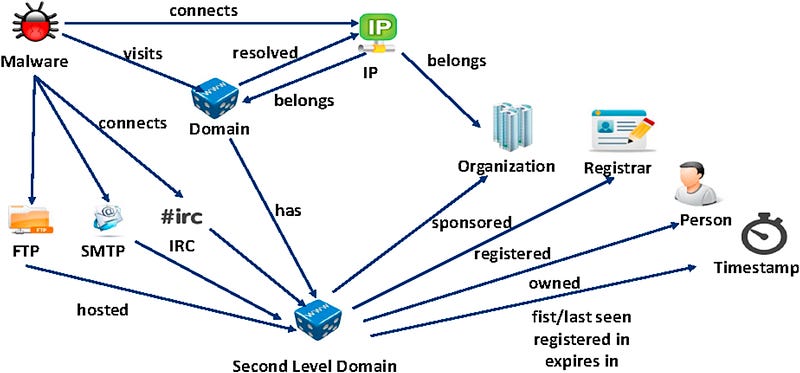
In order to abstract cyber threats, we can defined an infrastructure schema and where we define the linkages between the elements of intelligence gathering. In Figure 3 we see an example defined for a malware analysis infrastructure. This defines the elements of malware activity, such as for IP addresses, SMTP servers, timestamps, and domain owners.
In order to define linkages we often build a directed graph. In Figure 4 we have five nodes (1, 2, 3, 4 and 5) connected with seven edges [here]. A directed graph is defined is a digraph (or directed network) if the edges are bi-directional, or a a undirected graph is the edges go in one direction. An analyst might define Node 1 as a given IP address, and which is then linked to Node 3 which is a defined MAC address, and which links to Node 2 which is a given login identifier. This identifier could then be linked to Node 4, and which is a certain application identifier. Next this links to Node 5 which is associated with a given user ID. Finally this ID is then linked to the IP addressed defined as Node 1. We can then create complex graphics of known linkages, and where we can update with new links with new evidence or break them, when we find there is no linkages. Within digital investigations we often use this approach to gather evidence. For example, Bob is known to have purchased a car from Alice, and who bought it from Eve, and who is known to have a friendship with Bob.
Within cybersecurity we define the vertices as threats, such as for malware, domain owners and physical addresses (Boukhtouta, 2015). Each of the nodes can then have properties, such as for timestamps. In Figure 5 we see red vertices defining malware samples and which connects to domains (which are defined in blue). These result to domains (defined in yellow), and the green vertices represent owners, organisations and registrations.

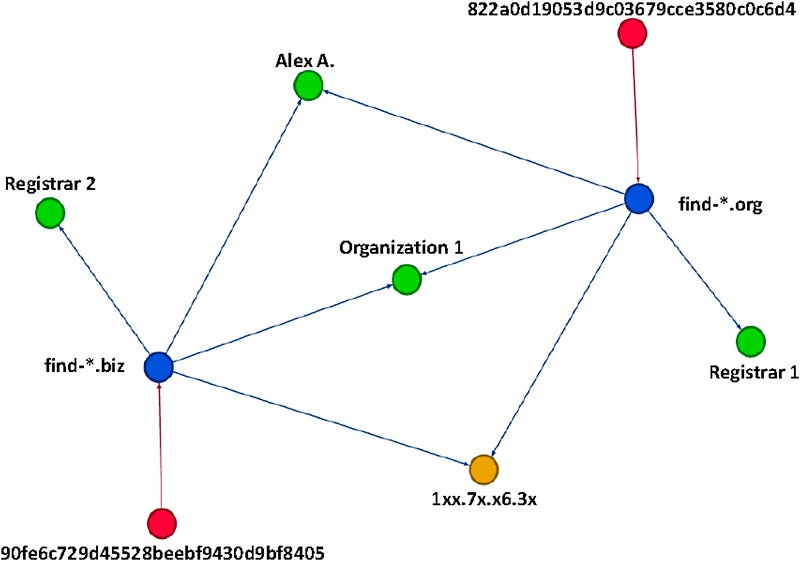
An analyst could then search for one element, and then be presented with other data elements which are associated. With a SIEM system, we might mine a single log entry in a Web server log of:
91.205.189.15 — — [26/Apr/2014:18:22:16] “GET /oldlink?itemId=EST-14&JSESSIONID=SD6SL7FF7ADFF53113 HTTP 1.1” 200 1665 “http://www.buttercupgames.com/oldlink?itemId=EST-14" “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.46 Safari/536.5” 159
Within this simple Web log Splunk is able to analyse all the Get HTTP method from the logs and picks off interesting fields of: action; bytes; categoryId; clientip; date_hour; date_mday; date_minute; date_month; date_second; date_wday; date_year; date_zone; file; host; ident; index; itemId; JSESSIONID; method; other; productId; punct; referer; referer_domain; req_time; source; sourcetype; splunk_server; status; timeendpos; timestartpos; uri; uri_path; uri_query ; user; useragent; and version.
And then use this as a pivot point to find a related association. For example, we might pivot-off the itemId, and find all the related IP addresses which also accessed the Web site using a specific value (in this case it is EST-14). In Figure 6we see an example of a search within Splunk for the GET HTTP method. The Web log entry is been defined with its discovered fields, the such as timestamp, and client IP address. For this event entry, we can see that the client IP addresses associated with GET request (from the HTTP Method field) are then defined. We could define the GET HTTP method as a node, and then these could like to defined IP addresses, or with defined TCP ports.

Conclusions
IBM pitch the idea of AI involving not replacing humans with machines, but in humans and machines working together. In cybersecurity, this needs to happen, and the core of this much of data analysis. We see the rise of our graduates going into analyst roles, and can only see this continue.
Postscript
If you are interested, here are some demos of Splunk:
References
Boukhtouta, Amine, et al. “Graph-theoretic characterization of cyber-threat infrastructures.” Digital Investigation 14 (2015): S3-S15.
Kelly, John E. “Computing, cognition and the future of knowing.” Whitepaper, IBM Reseach 2 (2015).