Similarity Matters!

In Data Science, Similarity Matters!
We often are searching for something and don’t quite know the actual form that it might take, or have misspelt it. You often trust Google to do this for you, and when you search for Edinburger and Casle, Google will often know which words match best based on the similarity to indexed terms and the probability of the words in searches:

But, in cybersecurity, similarity can often detect our No 1 threat: spear phishing, as a spear phishing email will often be created from a template, and then customized for the target.
The Basics
Often in data science, we need to find the similarity between two or more string. For example, we might want to match the string of “Celtic won the cup” with “The cup was won by Celtic”. For we can use string similarity methods. The most common methods are:
- Token. This involves finding similar blocks of text between two and uses this as a match. This method is strong when there is the same word within the two strings to be matched, but that they appear in different places. For example, it works very well for matching “Loans and Advances” with “Advances and Loans”.
- Jaro. This method works by analysing the number of character transpositions required between two strings.
- QGrams. This method involves analysing the number of similarities in n-length character sequences between two strings. It is similar in its operation to the Edit distance but performs well when the same prefixes are used between strings.
- Edit distance. This method analyses the number of changes required to go from one string to another. It works well when there number of changes between two strings, such as between “Loan and Account” and “Loans and Accounts”, which block methods often struggle with. Typically methods are Levenstein, Needleman-Wunch, Gotoh, Gotoh Window Affine, Jaro, Jaro Winkler, Qgram, Block, Cosine and Euclid.
Some of the key likely events are:
- Loss of insignificant word. This involves losing insignificant words such as “and”, “or”, “the”, and so on. The test used is “Loans and Accounts” and “Loans Accounts”.
- Small changes. This involves small changes in the words. The test used is “loans and accounts” and “loan and account”.
- Rearrangement of words. This involves moving the words around in the strings. The test used is “loans and accounts” and “accounts and loans”.
- Punctuation. This involves adding/removing punctuation marks. The test used for this is “fishing, “camping”; and ‘forest” and “fishing camping and forest”.
- Case. This involves analyzing the case of the characters. The test used for this is “Loan Account and Dealings” and “LOAN ACCOUNT AND DEALING”.
- Spacing. This involves changing the spaces between words. The test used for this is “LoanAccountDealing” and “Loan Account Dealing”.
The following figure outlines the different methods we can use:
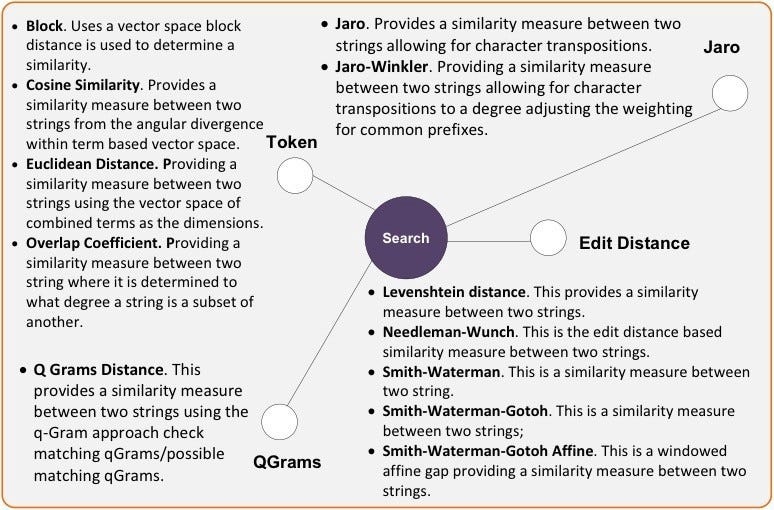
A scoring system for the methods is given in Table 1 [here]. A few conclusions can be drawn from this:
- The block methods generally work well with the loss of insignificant words, as they try to find the words wherever they are in the strings, where the distance methods struggle as they count the movements as a penalty for each change.
- The block methods also perform well with the rearrangement of words, as they are generally trying to find matching blocks.
- For small changes, the distance vector methods perform best, as only give a small penalty to one or two changes in a word, such as in making a word plural. The block methods often use a space as a and thus might miss a similar word if it is changed in a small way. The method also performs well here too.

So let’s try a few examples:
- Loss of insignificant words: “loans and accounts” and “loans accounts”. Try
- Small changes: “loans and accounts” and “loan and account”. Try
- Rearrangment of words: “loans and accounts” and “accounts and loans”. Try
- Punctuation: “fishing, “camping”; and ‘forest$” and “fishing camping and forest”. Try
- Case: “Loan Account and Dealing” “LOAN ACCOUNT DEALING”. Try
- Spacing: “LoanAccountDealing” “Load, Account, Dealing”. Try
- Spacing: “LoanAccountDealing” “Load, Account, Dealing”. Try
Here are another tests:
- Test: “The quick brown fox” and “The slow brawn fur”. Try
- Test: “Harry Potter” and “Potter Harry”. Try
Similarity hash
Many researchers have tried to find methods where they can hash a string and then compare the hashes. This allowed the content to be searched for and matched against to be represented in a hash form (and not in the original text). This makes it more efficient to store and to process. A good example is within a spam message, and where we receive two spam emails which only differ in the target’s contact name (taken from a real spam email):
Dear Sir, target@home !!
Reference #PP-003-AC7-993-014
Account Security Alret.
We need your help resolving an issue with your account.
What's going on?
Your debit or credit card issuer let us know that someone used your card without your permission. We want to make sure that you authorised any recent PayPal payments.
and:
Dear Sir, other@home !!
Reference #PP-003-AC7-993-014
Account Security Alret.
We need your help resolving an issue with your account.
What's going on?
Your debit or credit card issuer let us know that someone used your card without your permission. We want to make sure that you authorised any recent PayPal payments.
With this, we can use a similarity match to a known spam message, and gain a score. If the score goes over a certain level, we can quarantine it.
Charikar
Another method we can use is to create a hash value of a string, and then we can create a similarity hash. The Charikar similarity method is often used for documents and metadata in order to located duplicates or clustered objects. It uses strings in a list and where each word is a token. The order of the words does not matter. If we try the following:
- “word1 =”this is the first string”, word2 =”this is the first string” Try! We get a similarity of 1.0.
- word1 =”this is the first string”, word2 =”this is the string first” Try! We get a similarity of 1.0.
- word1 =”this is the first string”, word2 =”this is the first help” Try! We get a 256-bit similarity of 0.92.
- word1 =”this is the first string”, word2 =”this keep the first help”Try! We get a 256-bit similarity of 0.89.
Try here.
Nilsimsa
Nilsimsa is a similarity hash which is used as an anti-spam focused locality-sensitive hashing method [here]. This produces a score from 0 (dissimilar objects) to 128 (identical or very similar objects). Nilsima was created Damiani et al. in order to detect spam emails [here]. It uses a 5-byte fixed-size sliding window that analyses the input on a byte-by-byte and produces trigrams of possible combinations of the input characters.
The trigrams map into a 256-bit array (known as the accumulator) to create the hash, and every time a given position is accessed, its value is incremented. At the end of the processing, if the values are above a certain threshold, the value is set to a 1, else it will be zero. This produces a 32-byte digest.
To compare two hashes, the method checks the number of identical bits red to the same position. This produces a score from 0 (dissimilar objects) to 128 (identical or very similar objects).

Examples:
- “This is an email.”, “This is an email.” Score: 128 Try!
- “Hello Bill”, “hello bill” Score: 89 Try!
- “Dear Bill, You have won £10,000,000. Please email me back.”, “Dear Mark, You have won £10,000,000. Please email me back.” Score: 108 Try!
- “Dear Bill, You have won £10,000,000. Please email me back.”, “Dear Mark, You have won £10,000,000. Please email me back” Score: 107 Try!
- “The quick brown fox jumps over the lazy dog”, “ A quick brown fox jumps over the angry dog” Score: 86 Try!
- “This is a true email and I want you to contact me immediately”, “Hello. This is a true email and I want you to contact me immediately” Score: 76 Try!
- “Please be sure this is a sample email”, “Hello. This is to be sure this email is a sample” Score: 73 Try!
- This email conforms to all data protection standards.”, “All parts of data protection this Web conforms to.” Score: 52 Try!
- “Dear Bill, Please be ready to receive the money.”, “Dear Mark, I hope you are okay.” Score: 1 Try!
A sample run is:
Nilsimsa method
String 1: Dear Bill, You have won £10,000,000. Please email me back.
String 2: Dear Mark, You have won £10,000,000. Please email me back.
--------------
String 1 digest: 28af87350c35cd842f13c9bd70ba24e232aedc1e7610cef4ed436f342ba82afb
String 2 digest: 28af87370e25cd842f17c9bd62ba20e212aadc0e7690ced5e9036f342bac221b
Score: 108
Minhash
Minhash provides a measure of the resemblence between sets of data (Jaccard similarity). MinHash was created by Andrei Z. Broder [paper]. A sample run:
String 1: this is the first string
String 2: this is the first string
===================
Estimated Jaccard: 1.0
Actual Jaccard: 1.0
String 1: this is the first string
String 2: this is the string first
===================
Estimated Jaccard: 1.0
Actual Jaccard: 1.0
String 1: this is the first string
String 2: this is the string help
===================
Estimated Jaccard: 0.65625
Actual Jaccard: 0.666666666667
String 1: this is the first string
String 2: this keep the string help
===================
Estimated Jaccard: 0.4453125
Actual Jaccard: 0.428571428571
String 1: this is the first string
String 2: a totally different sentence
===================
Estimated Jaccard: 0.0
Actual Jaccard: 0.0
Conclusions
We increasing have to find data elements which are matched to each and need to assess the criteria for the match (such as not about the order of words or the case of the letters). The similarity methods defined here give a basic toolkit for integrating this analysis.
If you are interested we recently applied Damerau–Levenshtein Distance, Cosine Distance, and Jaccard Distance methods to the detection of insider threat detection in Cyber Security. You can read the paper here.