Pre-processing Your Data For Machine Learning using Splunk

Pre-processing Your Data For Machine Learning using Splunk
PCA and Standard Scaler
PCA (Principal Component Analysis) is a machine learning method that allows us to take multi-dimensional data and then map it into a much less complex space. For example we might have seven different variables within an IoT solution, and which would be difficult to visualise in seven dimensions. With PCA, we can reduce this down to two or three dimensions and which will make it easy to visualise.
Now, let’s use PCA to extract data for clustering for IoT data:

And then create a new experiment:

Next we load up our dataset with [here]:
| inputlookup track_day.csv
We can then see we have data relate to the “batteryVoltage”, “engineCoolantTemperature”, “engineSpeed”, “lateralGForce”, “verticalGForce”, “speed”, and “longitudeGForce” for different vehicle types:

As we can see all of data values have different ranges, so we can now normalise these with a pre-processing step:
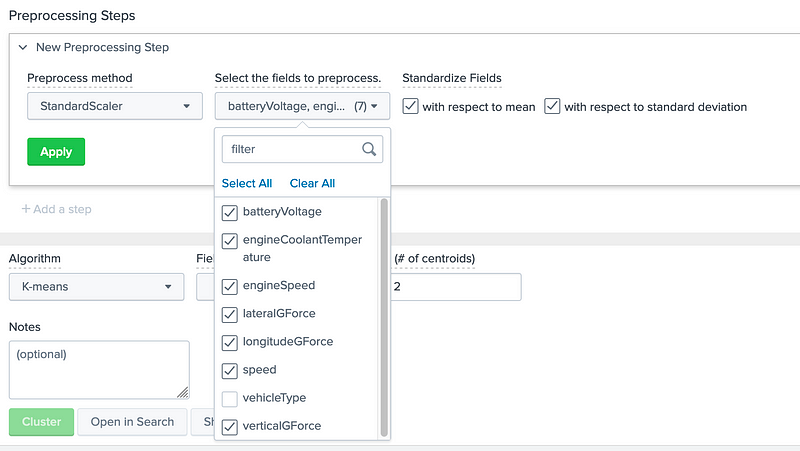
And then Apply. We should then see that the data is now scaled between zero and 1, and given a new identifier in the data set (such as SS_batteryVoltage):

We can now cluster with the new data set fields, and analyse:

This gives us our clustering, and where we see Cluster 1 grouping the battery voltage with the engine speed (the red dots):

PCA
Now, to reduce the complexity, we will add a Processing Step for PCA:

We then take our scaler values, and create the PCA pre-processing step:

Finally we define three PCA components:

Once we apply, we get three new PCA components in our dataset:

Next we will select our clustering algorithm:

After this, we select the three PCA fields (PC_1, PC_2 and PC_3) and K=6:

Finally, we run the Birch clustering method, and seperate into six clusters (0 to 5):

Our clustering now looks more clear-cut with natural clustering for PC_1 against PC_2. The SPL language for this shows the application of StandardScaler and PCA, and then using Birch:
| inputlookup track_day.csv
| fit StandardScaler “batteryVoltage”, “engineCoolantTemperature”, “engineSpeed”, “lateralGForce”, “verticalGForce”, “speed”, “longitudeGForce” with_mean=true with_std=true into _exp_draft_d557d94091de4f10b72c69bb9817b1a8_StandardScaler_1
| fit PCA “SS_batteryVoltage”, “SS_engineCoolantTemperature”, “SS_engineSpeed”, “SS_lateralGForce”, “SS_longitudeGForce”, “SS_speed”, “SS_verticalGForce” k=3 into _exp_draft_d557d94091de4f10b72c69bb9817b1a8_PCA_2
| fit Birch k=6 “PC_1” “PC_2” “PC_3” into “_exp_draft_d557d94091de4f10b72c69bb9817b1a8”
Conclusions
And there you go, PCA is a great tool in reducing the complexity of data inputs. If you are interested, we will be releasing a new Cyber&Data programme, and supported by The Data Lab. Here is a forthcoming course:
Eventbrite - The Cyber Academy presents Cyber & Data: Introduction to Cybersecurity and ML using Splunk - Wednesday, 1…www.eventbrite.co.uk
And if you didn’t know, underneath Splunk, you’ll find Python:
#!/usr/bin/env python
from sklearn.decomposition import PCA as _PCA
import pandas as pd
from base import BaseAlgo, TransformerMixin
from codec import codecs_manager
from util.param_util import convert_params
class PCA(TransformerMixin, BaseAlgo):
def __init__(self, options):
self.handle_options(options)
out_params = convert_params(
options.get(‘params’, {}),
ints=[‘k’],
floats=[‘variance’],
aliases={‘k’: ‘n_components’},
)
if ‘variance’ in out_params:
if ‘n_components’ in out_params:
msg = “Only one of k = {} or variance={} should be provided. Both cannot be respected.”.format(
out_params[‘n_components’], out_params[‘variance’]
)
raise RuntimeError(msg)
elif out_params[‘variance’] <= 0 or out_params[‘variance’] > 1:
msg = “Valid value for variance is 0 < variance <= 1”
raise RuntimeError(msg)
else:
# If we are doing PCA based on variance_ratio_explained, based on scikit-learn implementation,
# we set the n_components to that percentage, which will select the number of components such
# that the amount of variance that needs to be explained is greater than the percentage
# specified by n_components.
if 0 < out_params[‘variance’] < 1:
out_params[‘n_components’] = out_params[‘variance’]
del out_params[‘variance’]
self.estimator = _PCA(**out_params)
def rename_output(self, default_names, new_names):
if new_names is None:
new_names = ‘PC’
output_names = [‘{}_{}’.format(new_names, i + 1) for i in range(len(default_names))]
return output_names
def summary(self, options):
“”” Only model_name and mlspl_limits are supported for summary “””
if len(options) != 2:
msg = ‘“%s” models do not take options for summarization’ % self.__class__.__name__
raise RuntimeError(msg)
n_components = [‘PC_{}’.format(i + 1) for i in range(self.estimator.n_components_)]
return pd.DataFrame(
{
‘components’: n_components,
‘explained_variance’: self.estimator.explained_variance_.round(4),
‘explained_variance_ratio’: self.estimator.explained_variance_ratio_.round(4),
‘singular_values’: self.estimator.singular_values_.round(4),
},
index=n_components,
)
@staticmethod
def register_codecs():
from codec.codecs import SimpleObjectCodec
codecs_manager.add_codec(‘algos.PCA’, ‘PCA’, SimpleObjectCodec)
codecs_manager.add_codec(‘sklearn.decomposition.pca’, ‘PCA’, SimpleObjectCodec)