Machine Learning Prediction in Two Minutes: Perfectly Predicting Your Car

Machine Learning Prediction in Two Minutes: Perfectly Predicting Your Car
Your car is fairly unique. Well, the model of your car is fairly unique, as the manufacturer has set it up to drive in a certain way. A good car mechanic knows this, and will look for the car to run with its normal parameters, such as engine idle speed, normal vibrations from the engine, and so on. If any of these normal things vary outside the norm too much, it might indicate a fault.
So, if there’s one skill to pick up if your into Cybersecurity, it’s the usage of machine learning (ML), as the days of just using “the tool” to find things are gone. Often we need to find out what is normal and what is not. With the usage of ML, we can often easily find correlations within data sets that would be almost impossible using spreadsheets and standard tools. So, within Splunk —possibly the most popular cyber analytics tool — we have a whole suite of machine learning tools:
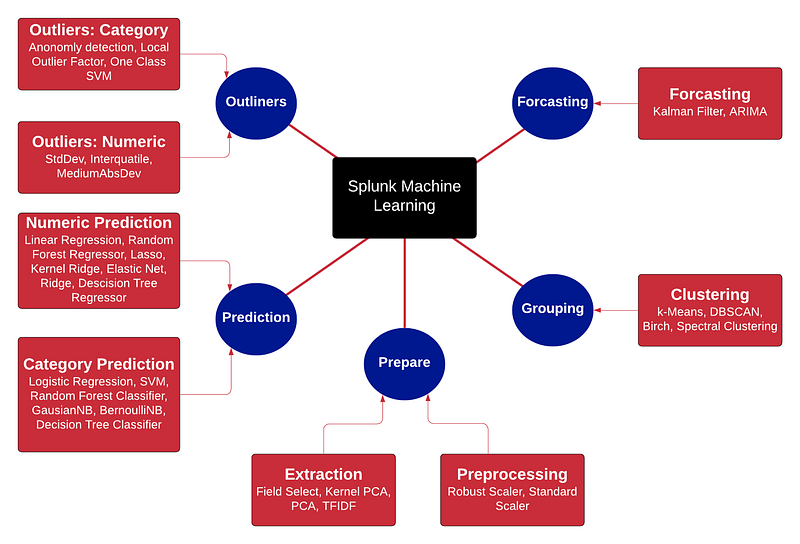
As we can see we can make predictions for numerical values, such as finding out the predicted temperature today at 12pm, or to predict categories, such as predicting the model of your car, based on collected data. Within category prediction there are a number of techniques we can use for our prediction including logistic regression, SVM (State Vector Model) and Random Forest Classification. Within logistic regression, we can to seperate the values into a number of categories, and then fit find the best solution.
So let’s take a data source of collected data from a race day, and see if we can predict the vehicle type. First, in Splunk, we will start a new experiment and select “Predict Categorial Fields”:

And then give our experiment a name:

Next we import the dataset, and see that it has 50,000 records:

In the data set we have five cars on a track day: 2008 BMW M3; 2011 Ferrari 458; 2011 Ford Mustang GT500; 2013 Audi RS5; 2014 Chevrolet Corvette; and a 2015 Porsche GT3. The collected numerical data include batteryVoltage, engineCoolantTemperature, engineSpeedlateral, GForcelongitude, GForcespeedvertical, and GForce:

Once populated, we can simply select logistic regression for our model:

And then for us to select the vehicleType field to predict:

And then use the numeric fields to predict this, and where we will use 70% of the data to train, and then 30% of the data to test our prediction:

Then we fit the model, and we get an accuracy of around 97% and where the car type prediction is correct around 97% of the time:

The SPL is simply:
| inputlookup track_day.csv
| fit LogisticRegression fit_intercept=true "vehicleType" from "batteryVoltage" "engineCoolantTemperature" "engineSpeed" "lateralGForce" "longitudeGForce" "speed" "verticalGForce" into "_exp_draft_d4292d86587049f2aeeb4c6db4d43545"
And so while the success rate for true positives is fairly good, if we then turn to Random Forest Classifier (and which is made up from a number of models), we get a perfect solution:

The SPL is simply:
| inputlookup track_day.csv
| fit RandomForestClassifier "vehicleType" from "batteryVoltage" "engineCoolantTemperature" "engineSpeed" "lateralGForce" "longitudeGForce" "speed" "verticalGForce" into "_exp_draft_d4292d86587049f2aeeb4c6db4d43545"
Conclusions
To go ML …