Jacob Ziv — The Man Who Compressed The World

Jacob Ziv — The Man Who Compressed The World
I am so pleased to see that Jacob Ziv has received the IEEE Medal of Honor. Along with Abraham Lempel, he created two lossless compression methods (LZ-77 and LZ-78) and which are the basis of a wide range of compressed file types including ZIP and GIF/PNG files. In many previous compression methods, there was some loss of bits when decompressing, but Lempel and Ziv found a way to compress data so that commonly occurring bit sequences could be represented by fewer bits than less common ones. Basically, if the sky is mainly blue with some white clouds, we give a short code for blue, and a longer one for white.
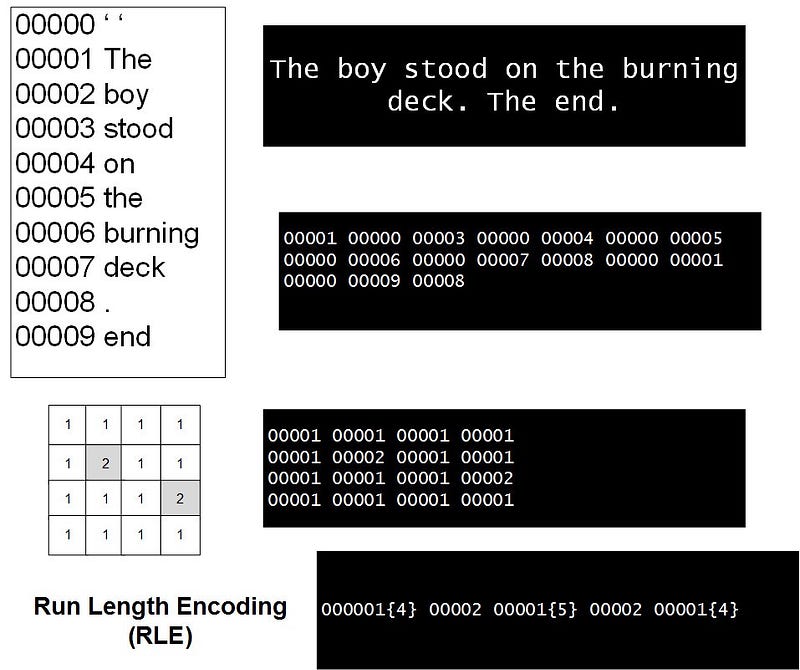
Around 1977, Abraham Lempel and Jacob Ziv developed the Lempel–Ziv class of adaptive dictionary data compression techniques (also known as LZ-77 coding), which are now some of the most popular compression techniques. The LZ-77 coding scheme is especially suited to data which has a high degree of repetition and makes back-references to these repeated parts. Typically a flag is normally used to identify coded and unencoded parts, where the flag creates back-references to the repeated sequence. An example piece of text could be:
‘The receiver requires a receipt for it. This is automatically sent when it is received.’
This text has several repeated sequences, such as ‘ is ’, ‘it’, ‘en’, ‘re’ and ‘ receiv’. For example, the repetitive sequence recei (as shown by the underlined highlight), and the encoded sequence could be modified with the flag sequence #m#n where m represents the number of characters to trace back to find the character sequence and n the number of replaced characters.
Thus, the encoded message could become:
‘The receiver#9#3quires a#20#5pt for it.This is automatically sent wh#6#2 it #30#2#47#5ved.’
Normally, a long sequence of text has many repeated words and phrases, such as ‘and’, ‘there’, and so on. Note that in some cases, this could lead to longer files if short sequences were replaced with codes that were longer than the actual sequence itself. Using the previous example of sports results:
Mulchester 3 Madchester 2
Smellmore Wanderers 60 Drinksome Wanderers 23
which could become:
Mulchester 3 Mad#13#7 2 Smellmore Wanderers 60 Drinksome#23#1123
The Lempel–Ziv–Welsh (LZW) algorithm (also known as LZ-78) builds a dictionary of frequently used groups of characters (or 8-bit binary values) [here]. Before the file is decoded, the compression dictionary is sent (if transmitting data) or stored (if data is being stored). In the following example we store the words in a table, and then refer to it in the store data:
Example
Let’s take a practical example:
Input: Cows graze in groves on grass which grows in grooves in groves
Compressed:
['C', 'o', 'w', 's', ' ', 'g', 'r', 'a', 'z', 'e', ' ', 'i', 'n', 260, 'r', 'o', 'v', 'e', 259, 'o', 268, 261, 'a', 's', 259, 'w', 'h', 'i', 'c', 'h', 269, 257, 259, 267, 286, 271, 273, 266, 276, 270, 272, 's']
Deompressed:
Cows graze in groves on grass which grows in grooves in groves
The first entry in the dictionary add position 256 will be ‘Co’, and next it will be ‘ow’. We can see that the following index values have been defined:
- The code ‘ g’ has been defined with an index of 260.
- The code ‘s ‘ has been defined with an index of 259.
- 268, 261 represents ‘n ‘ and ‘gr’, respectively.
The resulting dictionary entries that are added:
Adding: [256] Co
Adding: [257] ow
Adding: [258] ws
Adding: [259] s
Adding: [260] g
Adding: [261] gr
Adding: [262] ra
Adding: [263] az
Adding: [264] ze
Adding: [265] e
Adding: [266] i
Adding: [267] in
Adding: [268] n
Adding: [269] gr
Adding: [270] ro
Adding: [271] ov
Adding: [272] ve
Adding: [273] es
Adding: [274] s o
Adding: [275] on
Adding: [276] n g
Adding: [277] gra
Adding: [278] as
Adding: [279] ss
Adding: [280] s w
Adding: [281] wh
Adding: [282] hi
Adding: [283] ic
Adding: [284] ch
Adding: [285] h
Adding: [286] gro
Adding: [287] ows
Adding: [288] s i
Adding: [289] in
Adding: [290] groo
Adding: [291] ove
Adding: [292] es
Adding: [293] in
Adding: [294] n gr
Adding: [295] rov
Adding: [296] ves
LZ-78 (LZW)
The Lempel–Ziv–Welsh (LZW) algorithm (also known as LZ-78) builds a dictionary of frequently used groups of characters (or 8-bit binary values). Before the file is decoded, the compression dictionary is sent (if transmitting data) or stored (if data is being stored). This method is good at compressing text files because text files contain ASCII characters (which are stored as 8-bit binary values) but not so good for graphics files, which may have repeating patterns of binary digits that might not be multiples of 8 bits.
A simple example is to use a six-character alphabet and a 16-entry dictionary, thus the resulting code word will have 4 bits. If the transmitted message is:
ababacdcdaaaaaaef
Then, the transmitter and receiver would initially add the following to its dictionary:
0000 ‘a’ 0001 ‘b’
0010 ‘c’ 0011 ‘d’
0100 ‘e’ 0101 ‘f’
0110–1111 empty
First, the ‘a’ character is sent with 0000, next the ‘b’ character is sent and the transmitter checks to see that the ‘ab’ sequence has been stored in the dictionary. As it has not, it adds ‘ab’ to the dictionary, to give:
0000 ‘a’ 0001 ‘b’
0010 ‘c’ 0011 ‘d’
0100 ‘e’ 0101 ‘f’
0110 ‘ab’ 0111–1111 empty
The receiver will also add this to its table (thus, the transmitter and receiver will always have the same tables). Next, the transmitter reads the ‘a’ character and checks to see if the ‘ba’ sequence is in the code table. As it is not, it transmits the ‘a’ character as 0000, adds the ‘ba’ sequence to the dictionary, which will now contain:
0000 ‘a’
0001 ‘b’
0010 ‘c’
0011 ‘d’
0100 ‘e’
0101 ‘f’
0110 ‘ab’
0111 ‘ba’
1000–1111 empty
Next, the transmitter reads the ‘b’ character and checks to see if the ‘ba’ sequence is in the table. As it is, it will transmit the code table address which identifies it, i.e. 0111. When this is received, the receiver detects that it is in its dictionary and it knows that the addressed sequence is ‘ba’.
Next, the transmitter reads a ‘c’ and checks for the character in its dictionary. As it is included, it transmits its address, i.e. 0010. When this is received, the receiver checks its dictionary and locates the character ‘c’. This then continues with the transmitter and receiver maintaining identical copies of their dictionaries. A great deal of compression occurs when sending a sequence of one character, such as a long sequence of ‘a’.
Typically, in a practical implementation of LZW, the dictionary size for LZW starts at 4K (4096). The dictionary then stores bytes from 0 to 255 and the addresses 256 to 4095 are used for strings (which can contain two or more characters). As there are 4096 entries then it is a 12-bit coding scheme (0 to 4096 gives 0 to 212–1 different addresses).
Coding
The following outlines the coding:
import sys
## Based on http://rosettacode.org/wiki/LZW_compression#Python
message="Cows graze in groves on grass which grows in grooves in groves"
if (len(sys.argv)>1):
message=str(sys.argv[1])
def compress(uncompressed):
"""Compress a string to a list of output symbols."""
# Build the dictionary.
dict_size = 256
dictionary = dict((chr(i), chr(i)) for i in range(dict_size))
# in Python 3: dictionary = {chr(i): chr(i) for i in range(dict_size)}
w = ""
result = []
for c in uncompressed:
wc = w + c
if wc in dictionary:
w = wc
else:
result.append(dictionary[w])
# Add wc to the dictionary.
dictionary[wc] = dict_size
dict_size += 1
w = c
# Output the code for w.
if w:
result.append(dictionary[w])
return result
def decompress(compressed):
"""Decompress a list of output ks to a string."""
debug_str=""
# Build the dictionary.
dict_size = 256
dictionary = dict((chr(i), chr(i)) for i in range(dict_size))
# in Python 3: dictionary = {chr(i): chr(i) for i in range(dict_size)}
print(dict_size)
w = result = compressed.pop(0)
for k in compressed:
if k in dictionary:
entry = dictionary[k]
elif k == dict_size:
entry = w + w[0]
else:
raise ValueError('Bad compressed k: %s' % k)
result += entry
# Add w+entry[0] to the dictionary.
dictionary[dict_size] = w + entry[0]
debug_str += "Adding: ["+str(dict_size)+"]\t"+dictionary[dict_size]+"\n"
dict_size += 1
w = entry
print(dict_size)
return result,debug_str
print("Input: ",message)
compressed = compress(message)
print("\nCompressed:\n",compressed)
decompressed,debug_str = decompress(compressed)
print("\nDeompressed:\n",(decompressed))print("\n\nDebug")
print(debug_str)Here is an example:
In he example above, we have: Input: Cows graze in groves on grass which grows in grooves in groves Compressed: ['C'…asecuritysite.com
And here’s a cipher challenge: