C and C++: Still Alive and Kicking!

C and C++: Still Alive and Kicking!
For non-crypto hashing, it’s a winner.
I started out in software development with C, and it fitted me well as I moved from electronic engineering to software. For me, the power of bit twiddling and having the freedom to convert data into different formats was the real power of C. But … C has been responsible for so many problems in cybersecurity, especially related to buffer overflows and underflows. For example, what’s the problem with this code:
char buff[5];
strcpy(buff,"hello");
Well, we have reserved five places for data, and then fill with a string of five characters. Everything looks fine until you realise that we also have a null character (‘\0’) at the end of a string, in order to delimit it. Thus we have put six bytes into a data array which only holds five characters and have now written an extra byte to another area of data. If we had other variables in the program, an intruder could work out where they were and write data to them. It has been a long-running problem, and especially when we use pointers. For this we do the same:
char *buff = (char *) malloc(5);
strcpy(buff,"hello");
In this case, we now have a pointer (buff) to an area of memory where five bytes have been reserved. This is the same as the previous piece of code, but we now have the chance to dynamically allocate an area of memory in the code. I could go on for a while on the use of pointers, but I will stop here. When I used to teach C, everything went fine until the 5th lecture, in which I introduced pointers, and then the concept of passing pointers made teaching the topic all the harder. But, they are so powerful, and when it comes to writing core code, it is C that we often turn to. While we may convert to other languages, the core method is often laid down within the common denominator: C. It is cross-platform. It is fast. It links well to the hardware.
So I’ve been building some non-cryptography hashing functions from their C/C++ core and getting them tested against known tests. With a non-cryptography hash, we often take data, and convert it into a hashed value, and which will allow us to match strings. Often we can use this within a hash table, and where we hash our data and add the hash value to a table. As long as we do not have a collision — where different data produces the same hashed value — we can quickly search for data objects and match them. If you are Google, you may have massive amounts of data elements that you need to build into a table, and thus Google has been searching for a non-cryptography method that allows for fast processing within their Cloud infrastructure.
A city, a farm and a murmur
In 2011, Google released a fast hashing method in two main forms: CityHash64 (64-bit) and CityHash128 (128-bit). These are non-cryptography hashing methods but could be used for fast hash tables. Overall it is one of the fastest hashes without problems. Google generally produced a complex code and then optimized it for speed, especially on little-endian 32-bit or 64-bit CPUs. With little-endian, we organise the bytes of a value, so that the least significant byte is stored at the end. This suits Intel x68 and x86 architectures. Then, in 2014, Google have since released FarmHash as a successor to CityHash, and which had a number of enhancements.
xxHash was created by Yann Collet and is one of the fastest non-cryptography hashing methods. It uses a non-cryptographic technique. A significant speed improvement is achieved on processes that support SSE2, and which is an extension to the IA-32 architecture. This, of course, limits the architecture range for its implementation. Overall xxHash works at close RAM limits. In a recent test, xxH3 achieved a hashing rate of 31GB/s, and was especially efficient for a small amount of data (such as with text strings):

In the test, MUM (MUltiply and Mix) also achieved good levels of throughput. It was created by Vladimir Makarov in 2016 and designed for 64-bit CPUs. Overall many of the methods are based on the Murmur hash and was designed by Austin Appleby. It has a good performance compared with other hashing methods, and generally provide a good balance between performance and CPU utilization. Also, it performs well in terms of hash collisions.
Implementation
The following implements CityHash, FarmHash, xxHash, MUM and Murmur using different string inputs and seed values. The code is [here]:
#include <iostream>
#include <fstream>
#include <cstdlib>
#include <cstring>
#include "City.h"
#include "CityCrc.h"
#include "farmhash.h"
#include "farmhash-c.h"
#include "xxh3.h"
#include "xxhash.h"
#include "mum.h"
#include "farsh.h"
#include "MurmurHash1.h"
#include "MurmurHash2.h"
#include "MurmurHash3.h"
using namespace std;
typedef uint64_t uint64;
typedef uint32_t uint32;
typedef std::pair<uint64, uint64> uint128;
void byte_swap32(unsigned int* pVal32) {unsigned char* pByte;
pByte = (unsigned char*)pVal32;
// move lsb to msb
pByte[0] = pByte[0] ^ pByte[3];
pByte[3] = pByte[0] ^ pByte[3];
pByte[0] = pByte[0] ^ pByte[3];
// move lsb to msb
pByte[1] = pByte[1] ^ pByte[2];
pByte[2] = pByte[1] ^ pByte[2];
pByte[1] = pByte[1] ^ pByte[2];
}
#define BUFFSIZE 128
int main(int argc, char* argv[])
{
string str = "abc";
char buff[128];
uint32 u32;
uint64 u64;
uint128_c_t u128;
int seed = 0;
strcpy_s(buff, str.c_str());
if (argc >= 2) {
if (strlen(argv[1]) > BUFFSIZE-1) return(0);
strcpy_s(buff, argv[1]);
}
if (argc >= 3) seed = atoi(argv[2]);printf("String: %s\n", buff);
printf("Seed: %d\n\n", seed);puts("===City Hash===");
u64 = CityHash64(buff, strlen(buff));
printf("CityHash64:\t\t%llu Hex: %llx\n", u64, u64);
u64 = CityHash64WithSeed(buff, strlen(buff), (uint64)seed);
printf("CityHash64+seed:\t%llu Hex: %llx\n", u64, u64);uint128 seedv;
seedv.second = seed;
seedv.first = 0;
uint128 u128h = CityHash128(buff, strlen(buff));
printf("CityHash128:\t\t%llx%llx\n", u128h.first, u128h.second);
u128h = CityHash128WithSeed(buff, strlen(buff), seedv);
printf("CityHash128+seed:\t%llx%llx\n\n", u128h.first, u128h.second);
puts("===Farm Hash===");u32 = farmhash32(buff, strlen(buff));
printf("Farm32\t\t\t%ul Hex: %lx\n", u32, u32);
u32 = farmhash32_with_seed(buff, strlen(buff), (uint32_t)seed);
printf("Farm32+seed\t\t%ul Hex: %lx\n", u32, u32);
u64 = farmhash64(buff, strlen(buff));
printf("Farm64:\t\t\t%llu Hex: %llx\n", u64, u64);
u64 = farmhash64_with_seed(buff, strlen(buff), (uint64_t)seed);
printf("Farm64+seed:\t\t%llu Hex: %llx\n", u64, u64);
u128 = farmhash128(buff, strlen(buff));
printf("Farm128:\t\t%llx%llx\n", u128.b, u128.a);
uint128_c_t seedv2;
seedv2.a = seed;
seedv2.b = 0;
u128 = farmhash128_with_seed(buff, strlen(buff), seedv2);
printf("Farm128+seed:\t\t%llx%llx\n", u128.b, u128.a);
u32 = farmhash_fingerprint32(buff, strlen(buff));
printf("Farm32 fingerprint\t%lu Hex: %x\n", u32, u32);
u64 = farmhash_fingerprint64(buff, strlen(buff));
printf("Farm64 fingerprint\t%llu Hex: %llx\n", u64, u64);
u128 = farmhash_fingerprint128(buff, strlen(buff));
printf("Farm128 fingerprint:\t%llx%llx\n", u128.b, u128.a);
puts("\n===xxHash===");
XXH32_hash_t u32x = XXH32(buff, strlen(buff), (XXH32_hash_t)0);
printf("xx3Hash32\t\t\t%ul Hex: %lx\n", u32x, u32x);
u32x = XXH32(buff, strlen(buff), (XXH32_hash_t)seed);
printf("xx3Hash32+Seed\t\t\t%ul Hex: %lx\n", u32x, u32x);XXH64_hash_t u64x = XXH64(buff, strlen(buff), (XXH64_hash_t)0);
printf("xx3Hash64\t\t\t%lld Hex: %llx\n", u64x, u64x);
u64x = XXH64(buff, strlen(buff), (XXH64_hash_t)seed);
printf("xx3Hash64+Seed\t\t\t%llu Hex: %llx\n", u64x, u64x);
XXH128_hash_t u128x = XXH128(buff, strlen(buff), (XXH64_hash_t)0);
printf("xx3Hash128\t\t\t%llx%llx\n", u128x.high64, u128x.low64);
u128x = XXH128(buff, strlen(buff), (XXH64_hash_t)seed);
printf("xx3Hash128+Seed\t\t\t%llx%llx\n", u128x.high64, u128x.low64);
puts("\n===Mum===");
uint64_t u64m = mum_hash(buff, strlen(buff), (uint64_t)0);
printf("Mum\t\t\t%llu Hex: %llx\n", u64m, u64m);puts("\n===Murmur===");
uint32_t u32m = MurmurHash1(buff, strlen(buff),(uint32_t)0);
printf("MurmurHash1:\t\t\t%ul Hex: %lx\n", u32m, u32m);u32m = MurmurHash1(buff, strlen(buff), (uint32_t)seed);
printf("MurmurHash1+Seed:\t\t\t%ul Hex: %lx\n", u32m, u32m);
u32m = MurmurHash2(buff, strlen(buff), (uint32_t)0);
printf("MurmurHash2:\t\t\t%ul Hex: %lx\n", u32m, u32m);
u32m = MurmurHash2(buff, strlen(buff), (uint32_t)seed);
printf("MurmurHash2+Seed:\t\t\t%ul Hex: %lx\n", u32m, u32m);
uint32_t h1;
MurmurHash3_x86_32(buff, strlen(buff),0, &h1);
printf("MurmurHash3 32 bit:\t\t\t%ul Hex: %lx\n", h1, h1);
MurmurHash3_x86_32(buff, strlen(buff),(uint32_t) seed, &h1);
printf("MurmurHash3 32+Seed:\t\t\t%ul Hex: %lx\n", h1, h1);
uint32_t h2[4];
MurmurHash3_x86_128(buff, strlen(buff), 0, h2);
byte_swap32(&h2[0]); byte_swap32(&h2[1]); byte_swap32(&h2[2]); byte_swap32(&h2[3]);
printf("MurmurHash3 128 bit (x86):\t\t%lx%lx%lx%lx\n", h2[0], h2[1], h2[2],h2[3]);
MurmurHash3_x86_128(buff, strlen(buff),(uint32_t)seed, h2);
byte_swap32(&h2[0]); byte_swap32(&h2[1]); byte_swap32(&h2[2]); byte_swap32(&h2[3]);
printf("MurmurHash3 128 bit (x86)+Seed:\t\t%lx%lx%lx%lx\n", h2[0], h2[1], h2[2], h2[3]);
MurmurHash3_x64_128(buff, strlen(buff), 0, h2);
byte_swap32(&h2[0]); byte_swap32(&h2[1]); byte_swap32(&h2[2]); byte_swap32(&h2[3]);
printf("MurmurHash3 128 bit (x68):\t\t%lx%lx%lx%lx\n", h2[0], h2[1], h2[2], h2[3]);
MurmurHash3_x64_128(buff, strlen(buff), (uint32_t)seed, h2);
byte_swap32(&h2[0]); byte_swap32(&h2[1]); byte_swap32(&h2[2]); byte_swap32(&h2[3]);
printf("MurmurHash3 128 bit (x68)+Seed:\t\t%lx%lx%lx%lx\n", h2[0], h2[1], h2[2], h2[3]);
}
Within most compilers, we can represent our integer values with 8-bit (char), 16-bit (int) 32-bit (long) or 64-bit (long long). In crypto, we typically only deal with unsigned integers. These types in C are represented with uint16, uint32, and uint64 (and based on the types such as uint32_t, uint64_t). We also need 128-bit values, and thus have a type of uin128, and which comprises of two 64-bit values. In the following we see we use .first and .second properties to access the values:
uint128 u128h = CityHash128(buff, strlen(buff));
printf("CityHash128:\t\t%llx%llx\n", u128h.first, u128h.second);
u128h = CityHash128WithSeed(buff, strlen(buff), seedv);
printf("CityHash128+seed:\t%llx%llx\n\n", u128h.first, u128h.second);
In terms of displaying the values, we use “lx” for a 32-bit hexadecimal value and “llx” for a 64-bit hexadecimal value. The following is a test run [here]:
String: test
Seed: 12345
===City Hash===
CityHash64: 8581389452482819506 Hex: 7717383daa85b5b2
CityHash64+seed: 9154302171269876511 Hex: 7f0a9d52bd20cb1f
CityHash128: 1139ce35096d0ba4fbeff23c90eadf08
CityHash128+seed: 44fd5affdcbc45429bc32b45e0de2036
===Farm Hash===
Farm32 168770635l Hex: a0f3c4b
Farm32+seed 687740529l Hex: 28fe1671
Farm64: 656818571139125405 Hex: 91d7d02aea0909d
Farm64+seed: 1329645378812687902 Hex: 1273d96d615eb61e
Farm128: d12ec84f0de22211bafd8a901d3c45d6
Farm128+seed: f7010817419b84812858cc83ab42283
Farm32 fingerprint 1633095781 Hex: 61571065
Farm64 fingerprint 8581389452482819506 Hex: 7717383daa85b5b2
Farm128 fingerprint: fbeff23c90eadf081139ce35096d0ba4
===xxHash===
xx3Hash32 1042293711l Hex: 3e2023cf
xx3Hash32+Seed 3834992036l Hex: e49555a4
xx3Hash64 5754696928334414137 Hex: 4fdcca5ddb678139
xx3Hash64+Seed 7624679986283906467 Hex: 69d04e0cdc7b85a3
xx3Hash128 6c78e0e3bd51d358d01e758642b85fb8
xx3Hash128+Seed dae76db4003dd6b4ea8302d5faaaf2b9
===Mum===
Mum 12122843130624056202 Hex: a83cfd9904a19b8a
===Murmur===
MurmurHash1: 1706635965l Hex: 65b932bd
MurmurHash1+Seed: 3510673532l Hex: d140a07c
MurmurHash2: 403862830l Hex: 1812752e
MurmurHash2+Seed: 3122340370l Hex: ba1b2212
MurmurHash3 32 bit: 3127628307l Hex: ba6bd213
MurmurHash3 32+Seed: 3262196943l Hex: c2712ccf
MurmurHash3 128 bit (x86): 30ef026f687d0c55687d0c55687d0c55
MurmurHash3 128 bit (x86)+Seed: c32efba3bcac4b6ebcac4b6ebcac4b6e
MurmurHash3 128 bit (x68): 9de1bd74cc287dac824dbdf93182129a
MurmurHash3 128 bit (x68)+Seed: 6c71b1442bd402d1bedf5ce954e92ead
In order to validate the output, we need to look at published test vectors. For Murmur we have some test vectors here.

Thus a message of “The quick brown fox jumps over the lazy dog” produces “6C1B07BC7BBC4BE347939AC4A93C437A” Try. We can see this works here:
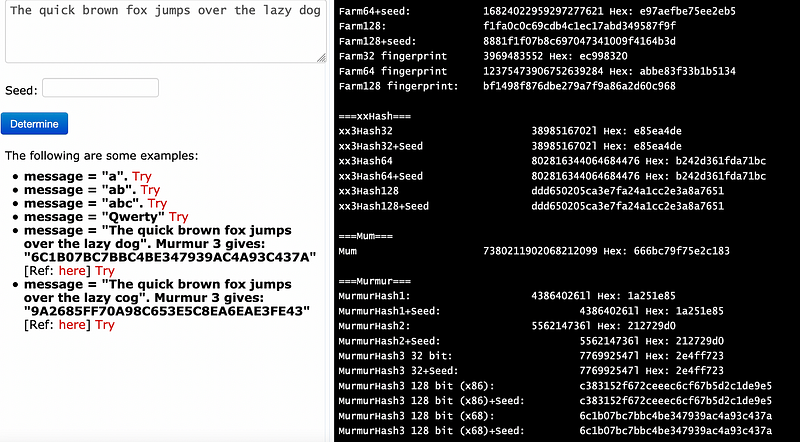
If you have Visual Studio, you can download the solution here.

Conclusions
When it comes down to it, we need code that can run on a range of systems, and, often, to take advantage of hardware advances. For this, we often turn to the lowest-common denominator: C and C++. If you are into cybersecurity, I’d say C (for low-level things) and Python (for most other things) are two of the most useful languages to have expertise in.