Load balancing, Hashtables and Consistent Hashing

Load balancing, Hashtables and Consistent Hashing
I may be wrong, but at the core of this is technical and scientific excellence, and in addressing problems with new methods, or by using existing methods in new ways. Too often, technologists just focus on the methods they know and then try and match these to the problem, but a true innovator finds the tools/methods which fit the problem. So, let’s look at something that disrupted and trace its roots: hash tables and consistency hashes.
Hashtables
A hash table is a fast and efficient way to find and map data objects. If we have banking transactions, we can simply hash the transaction, and this hash value then becomes the index (or key) for the transaction. A great advantage of this is that we can then distribute our data infrastructure, and then maintain a consistent hash table across the whole infrastructure. We thus can create a hashtable with a number of slots (m), and where we map a number of keys (n). In the hashtable, we then get a key-value mapping for our data.
In a hashtable, we need to decide the total number of key pairs we wish to store. We thus end up with an array of m slots, and where we create a hash key then map this to a slot location in the array:
hash_value = key (mod m)
For 998 slots, we select a prime number (m) of 997, and map the key to the hash with:
Key — Hashing_method — Hash
4314—4313 (mod 997) — 326
99999—99999 (mod 997) — 299
99964 — 99964 (mod 997) — 264
19964 — 19964 (mod 997) — 24
19764 — 19764 (mod 997) — 821
49763 — 49763 (mod 997) — 910
The hash then defines the slot number, and which should contain the data element. In the following, we have four slots, and where the data key is then hashed with a mod operation to produce the slot number in the array for the data mapping:

Overall, we do not need to search for our data element, we just need to hash it and then take the (mod) operation. This means that we can create vast data structures, and which will have the same access time no matter the number of data elements that we have.
Consistent hashes
Overall, the more slots we have, the smaller the chance there will be of finding a collision (and where different data objects result in the same hash_value). Unfortunately, in most hash table methods, if we need to grow the number of slots, we will have to remap most of the keys. This problem is overcome with the concept of a consistent hash, and where only n/m keys will need to be remapped. It was termed by David Karger in 1997 [here]:

For David, the application was related to servers within a distributed infrastructure, and where each server was identified by a hashed value. His method allowed a server to be added or deleted with just a change of keys/slot items. Many researchers took the method forward, including Daniel Lewin [1]— one of the co-creators of Akamai Technologies — who used it for caching data in distributed networks [here]:

Akamai found that a consistent hashing method allowed them to load balance content across a number of servers. The method is also integrated into DHTs (distributed hash tables), and where the keys can be partitioned to a cluster of nodes. This just requires an overlay infrastructure to map a key to the required cluster node with the required hashtable.
In Python 3 (based on this code here), we can assign five servers, and then hash the keys to locate the required server [here]:
from hashlib import sha256
from bisect import bisect
class Ring(object):
def __init__(self, server_list, num_replicas=5):
nodes = self.generate_nodes(network_servers, num_replicas)
hnodes = [self.hash(node) for node in nodes]
hnodes.sort()
self.num_replicas = num_replicas
self.nodes = nodes
self.hnodes = hnodes
self.nodes_map = {self.hash(node): node.split("-")[1] for node in nodes}
@staticmethod
def hash(val):
m = sha256(val.encode())
return int(m.hexdigest(), 16)
@staticmethod
def generate_nodes(server_list, num_replicas):
nodes = []
for i in range(num_replicas):
for server in server_list:
nodes.append("{0}-{1}".format(i, server))
return nodes
def get_node(self, val):
pos = bisect(self.hnodes, self.hash(val))
if pos == len(self.hnodes):
return self.nodes_map[self.hnodes[0]]
else:
return self.nodes_map[self.hnodes[pos]]
network_servers = ["192.168.0.1", "192.168.0.2", "192.168.0.3","192.168.0.4","192.168.0.5"]
ring = Ring(network_servers)
print ("Bob1\t\t",ring.get_node("Bob1"))
print ("Bob2\t\t",ring.get_node("Bob2"))
print ("Alice123\t",ring.get_node("Alice123"))
print ("Eve455\t\t",ring.get_node("Eve455"))
print ("Dave543\t\t",ring.get_node("Dave543"))A sample run gives:
Bob1 192.168.0.2
Bob2 192.168.0.4
Alice123 192.168.0.4
Eve455 192.168.0.1
Dave543 192.168.0.1While the node at 192.168.0.3 doesn’t have any data objects in this case, when we scale up, the loading will generally be even across the cluster.
The method
Every data object then gets assigned to the next server in the circle — and thus we will load balance for the server.
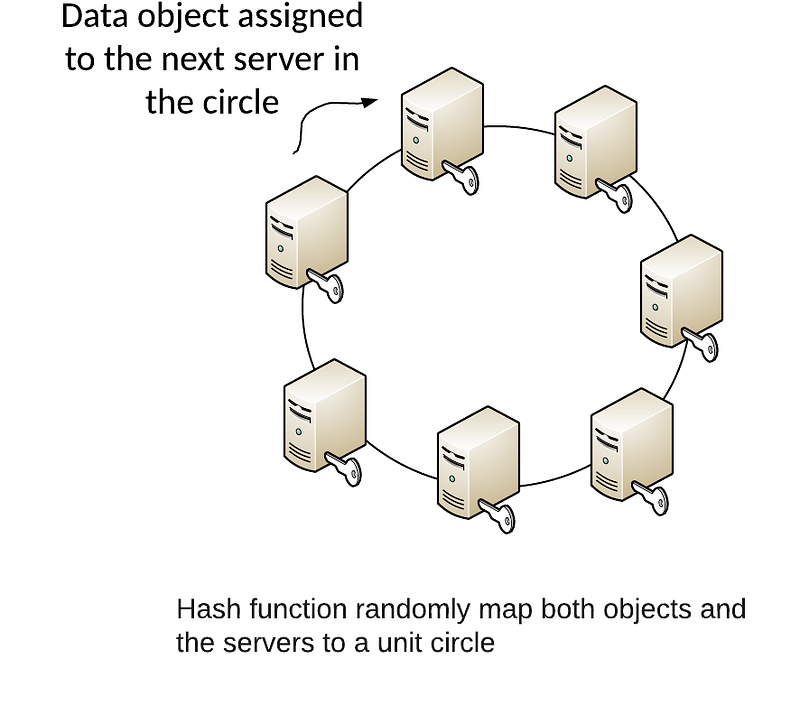
When a server crashes or is removed, all of the data elements of that server now need to be assigned to the next server in a clockwise direction. For a new server in the circle, we only need to map new data objects to it. If there are many servers, there will be minimal movement of data objects if there is a new server added or one deleted. In order for too much load to be placed on the server that is clockwise from a failed server, we can hash the server entity so that it can appear in multiple locations in the server. In this way, we will reduce the load on servers where there are failures.
In the example above we have seven servers, and each could be given an angle in the ring at 0 deg (Server A), 51.4 deg (Server B), 102.8 deg (Server C), and so on. When we hash, we determine the angle and then find the server which has the nearest angle. If we add a new server, the angle between the servers will decrease, and when we delete a server, the angle will increase. But we do not need to change the keys for Server B at 51.4 deg, as a new one could be placed at 25 deg (Server X), and in between the first server and the previous second server in the circle. If we delete Server B, then the next highest angle will be Server C, and where the circle will still be consistent, and where there is no need to change the keys for Server C.
Conclusions
In just a couple of decades, we built a new world. It was not one based on legacy data infrastructures where we had a server and data, but one where we could cluster servers and add and delete them as required. It was one where we balanced the load. From there, we build the Web — one of the most amazing structures that humankind has ever built. Out went our static sources of knowledge — books, and libraries — and in came the distribution of knowledge. It was one that did not limit knowledge to the privileged few but allowed access to it from the access to an IP address.
So, sometimes stand back, and look at things with new eyes, and from there you can build something new. My little tip to early career researchers is never to dismiss methods from the past but to also look to the new research which is making an impact. Have a look at the citation count for a paper, and if it is just recently published, and the citation count is fairly high, you know there could be something in there. For the methods of the past, read the classic papers and implement their methods, and see why they have become a classic.
Postscript
[1] Daniel (Danny) Lewin lost his life on 11 September 2001 (9/11) on American Airlines Flight 11. It is thought that he was stabbed by one of the hijackers, after attempting to foil their execution. He sat in seat 9B on the day, and which was close to the hijackers. In this memory, the street between Main and Vassar Streets in Cambridge is named after him:
