How Facebook Took Themselves Off The Internet … A Lesson In Resiliance And A Need To Decentralise

How Facebook Took Themselves Off The Internet … A Lesson In Resilience And A Need To Decentralise
In a post-pandemic world, one thing that we are now sure of is that we are almost completely dependent on the Internet for both our social and working lives. Over the past few decades, it has embedded itself into our lives, and we would struggle to be without it for any amount of time. ‘Digital-by-default’ has become the focus for many things, but when you can’t even connect to an online service, we often have little to fall back on. While it might be inconvenient to lose your Facebook posts for a few hours, it is not so good to bring down a nation’s transport or health care infrastructure.
So the Internet isn’t the large-scale distributed network that DARPA tried to create, and which could withstand a nuclear strike on any part of it. At its core is a centralised infrastructure of routing devices and of centralised Internet services. The protocols its uses are basically just the ones that were drafted when we connected to mainframe computers from dumb terminals. Overall, though, a single glitch in its core infrastructure can bring the whole thing crashing to the floor. And then if you can’t get connected to the network, you often will struggle to fix it. A bit like trying to fix your car, when you have locked yourself out, and don’t have the key to get in.
For our future resilience, we perhaps need to look at truly decentralised methods, and which can withstand the domino effect of one service pulling down others. The core is there, and we now need to think about resilience at every level of our access to the Internet and its services. Basically, the Internet is too important to fail.
Facebook takes itself off the Internet … blame BGP
In Cybersecurity, you are taught about CIA … and that’s Confidentiality, Integrity … and most importantly Availability. But here we are after nearly five decades of the Internet, and it is availability that we are really struggling with. If it’s not a routing problem, it’s a DNS problem, or a server problem, or a power failure, or …
And so, yesterday, at around 5pm (UTC), the Facebook empire crumbled a little bit, and actually showcased how fragile our infrastructure is. The outage of its main revenue services of Facebook, WhatsApp and Instagram went on for around five hours, and, perhaps, highlights that the core of the Internet is a long way from being as resilient as our other core services that are essential for our work (energy, transport, etc). For Facebook, it was a massive loss of revenue in a single instance, and for the fact that it took them five hours to fix.
Basically their infrastructure — like many — fell like a house of cards when one of the core elements failed. And when these services fail, even the ability to debug the fault fails too, as there is basically a lack of core connectivity. The Internet we have thus created has lots of interconnections, and when one element fails, it can bring down the other elements.
A typical cause … a config error
For the Facebook outage, it looks like it was all down to a configuration change within back-end routers that connected to their data centres. And once they had lost the connectivity and debug facilities, it was difficult to trace the fault and fix it. I have personally had to plug in RS-232 terminal connections in Cloud infrastructures as there was no other way to connect to them. If a network connection fails from a device, sometimes the only option is to get your laptop out and plug it in to get network connectivity.
At the root of the problem is likely to be a BGP (Border Group Protocol) update, and which did not allow the update to be revert and blocked network access with the Facebook domain. This meant that Facebook engineers struggled to be connectivity to fix the problem.
BGP does the core of routing on the Internet, works by defining autonomous systems (AS). The ASs are identified with an ASN (Autonomous System Number) and keep routing tables which allows the ASs to pass data packets between themselves, and thus route between them. Thus the Facebook AS can advertise to other AS’s that it exists and that packets can be routed to them. When the Facebook outage happened, the Facebook AS failed to advertise its presence. Each AS then defines the network ranges that they can reach. Facebook’s ASN is AS32935 and covers around 270,000 IP address ranges [here].
At around 5 pm UTC, the Facebook network stopped announcing its routes which meant that its DNS servers become unavailable. This meant that Facebook could not advertise the IP addresses of the servers, and all of the DNS servers on the Internet then dropped the name resolution. While the servers could still be contacted by their IP address, there was no way they could be resolved with a domain name.
Cloudflare traced the bug to 3:40pm, and where there was a spike in the number of BGP updates:
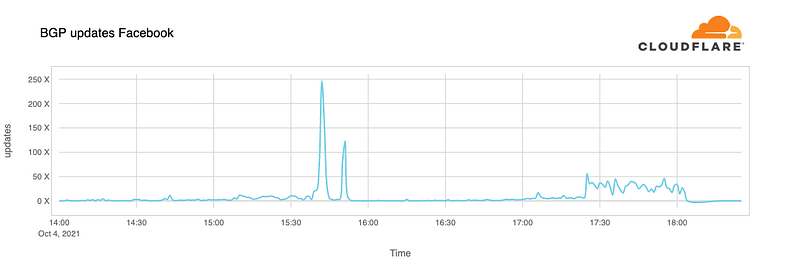
Basically, Facebook’s AS started to send out a withdrawal of routes and which then stopped their DNS servers from resolving their associated domain names. As Facebook is responsible for resolving these, the lack of response meant that DNS servers across the Internet aged out their domain name resolution, and which meant that users could not contact their services. So lots of services around the world started to problem the lack of connectivity, and this was observed by Cloudflare:

This resulted in a nearly 30-fold increase in traffic for DNS resolution for Facebook’s services, and which could have been enough to bring down DNS servers, but the network coped, and only Facebook’s services were affected. Cloudflare, too, looked at the cascading of social media, and where users turned to other online services for the social media reporting:

In the end, Cloudflare saw another glitch in BGP traffic from Facebook around 9:17pm (UTC), and which identified that Facebook has fixed the problem.
Conclusions
At its core, the Internet is not a decentralised infrastructure. It is fragile and open to human error and adversarial attacks. Too much of our time is spent on making our services work and very little on making them robust. We need to spend more time looking at scenarios and how to mitigate them. This time it was Facebook taking themselves offline, the next time it could be a nation-state bring down a whole country … and that it is likely to have a devastating effect.
We perhaps need to redesign and remap our Internet and look towards services that do not rely on our existing centralised approaches. That is one reason we are looking at IPFS in our GLASS problem, and which moves away from URLs and centralised services:
If it takes Facebook will all their resources five hours to get their infrastructure back online, your must worry about our health care infrastructure, our government services, our energy supply network, our education system … and so many critical services. A few years ago, we looked at the resilience of DNS, and in how DNS servers could be brought down by a denial of service attack. This would come from an attack, or from basic human error.