For The Love of Digital Forensics: Where Would You Find 1111 1111 1111 and “ID3"?

For The Love of Digital Forensics: Where Would You Find 1111 1111 1111 and “ID3"?
Well, the answer is, in an MP3 file. With audio, we normally sample at twice the highest frequency of the signal, and so if we have hi-fi quality audio we normally define a 22kHz bandwidth (as this is the range your ear can hear). Then our sampling rate becomes around 44.1kHz, which gives us one sample every 22 microSeconds. Each sample has 16 bits and two channels, and so the rate we require for raw high-quality audio is 1.4 Mbps. This would be a high requirement for many systems and is generally wasteful. So, we compress this down by performing a DCT (Discrete Cosine Transform).
Psycho-acoustic model
MPEG and Dolby AC-3 use the psycho-acoustic model to reduce the data rate, which exploits the characteristics of the human ear. This is similar to the method used in MPEG video compression which uses the fact that the human eye has a lack of sensitivity to the higher-frequency video components (that is, sharp changes of colour or contrast). The psycho-acoustic model allows certain frequency components to be reduced in size without affecting the perceived audio quality as heard by the listener.
A well-known effect is the masking effect. This is where noise is only heard by a person when there are no other sounds to mask it. A typical example is a high-frequency hiss from a compact cassette when there are quiet passages of music. In normal periods of music, the louder music masks out the quieter hiss and the noise is not heard. In reality, the brain is actually masking the part of the sound it wants to hear, although the noise component is still there. When there is no music to mask the sound then the noise is heard.
Noise, itself, tends to occur across a wide range of frequencies, but the masking effect also occurs with certain sounds. A loud sound at a certain frequency masks out a quieter sound at a similar frequency. Therefore the sound heard by the listener appears only to contain the loud sounds; the quieter sounds are masked out. The psycho-acoustic model tries to reduce the levels to those that would be perceived by the brain.
Figure 1 illustrates this psycho-acoustic process. In this case, a masking level has been applied and all the amplitudes below this level have been reduced in size. Since these frequencies have been reduced in amplitude, then any noise associated with them is also significantly reduced. This has the effect of limiting the bandwidth of the signal to the key frequency ranges and also limiting the noise bandwidth.
The psycho-acoustic model also takes into account non-linearities in the sensitivity of the ear. Its peak sensitivity is between 2 and 4kHz (the range of the human voice) and it is least sensitive around the extremes of the frequency range (i.e. high and low frequencies). Any noise in the less sensitive frequency ranges is more easily masked, but it is important to minimize any noise in the peak range because it has a greater impact.
Masking can also be applied in the time domain, where it is applied just before and after a strong sound (such as a change of between 30 and 40dB). Typically, premasking occurs for about 2–5ms before the sound is perceived by the listener and the post-masking effect lasts for about 100ms after the end of the source.

MPEG levels
MPEG basically has three different levels:
- MPEG-Audio Level I — uses a psycho-acoustic model to mask and reduce the sample size. It is basically a simplified version of MUSICAM and has a quality which is nearly equivalent to CD-quality audio. Its main advantage is that it allows the construction of simple encoders and decoders with medium performance and which operate well at 192 or 256kbps.
- MPEG-Audio Level II — which is identical to the MUSICAM standard. It is also nearly equivalent to CD-quality audio and is optimized for a bit rate of 96 or 128kbps per monophonic channel.
- MPEG-Audio Level III — which is a combination of the MUSICAM scheme and ASPEC, a sound compression scheme designed in Erlangen, Germany. Its main advantage is that it targets a bit rate of 64kbps per audio channel. At that speed, the quality is very close to CD quality and produces a sound quality which is better than MPEG Level-II operating at 64kbps.
We MP3 encoding, we basically take the samples and then bundle these together to create frames of samples. In Figure 2, we see that each frame has 1,152 samples.
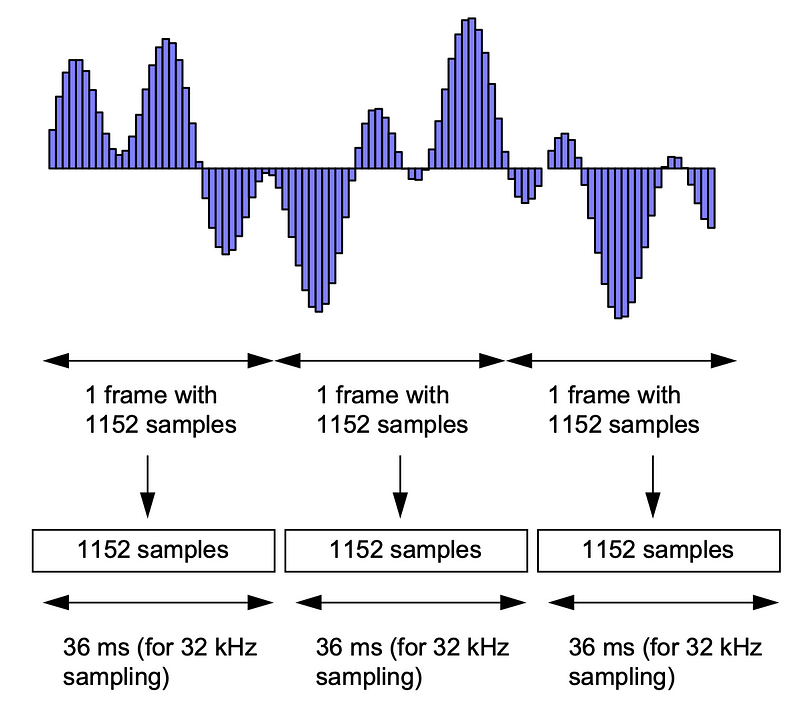
The basic MPEG-1 audio frame, after encoding, includes four basic types of information:
- A header.
- A cyclic redundancy code (CRC) for error detection.
- Audio data.
- Ancillary data.
The MPEG file also contains bit allocation information, scale factor selection information, scale factors, and subband samples.
MP3 file formats
The MP3 file format that we use in playing audio creates a 32-bit header for each of the data frames. Each file can either have an ID3 header file to identify the details of the song, or not (Figure 3).

To identify that we are at the start of a frame, the bitstream starts with 12 1’s, followed by the version, the MP3 layer, error protection, the bit rate, and the sampling rate. In the example in Figure 3, we see that a value of 1010 identifies a bit rate of 160 Mbps, and 11 gives us a sampling rate of 44kHz.
So, let’s take an example from here:
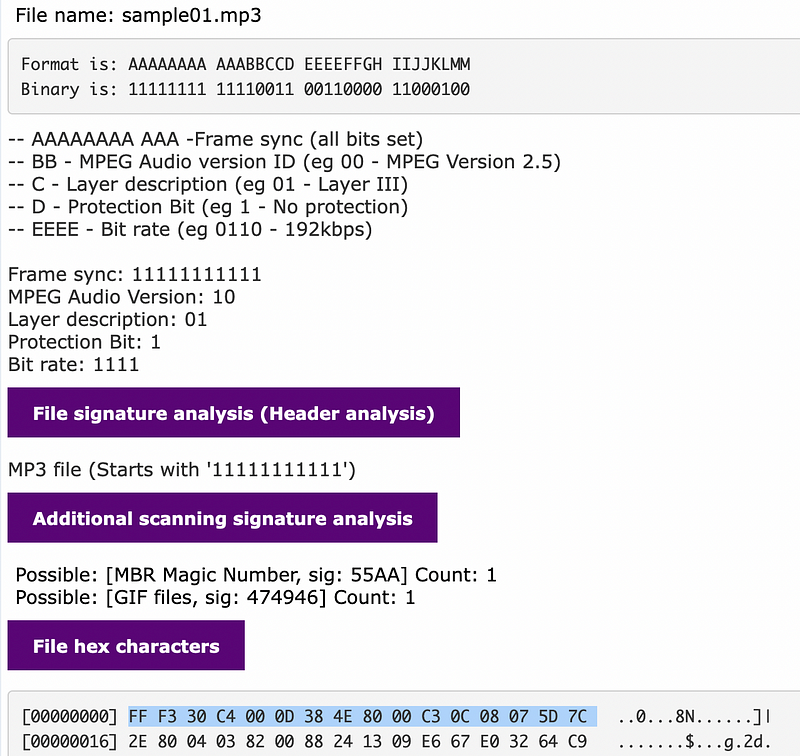
We see the first four bytes are FF F3 30 C4:
Format is: AAAAAAAA AAABBCCD EEEEFFGH IIJJKLMM
Binary is: 11111111 11110011 00110000 11000100
Thus we get:
-- AAAAAAAA AAA -Frame sync (all bits set)
-- BB - MPEG Audio version ID (eg 00 - MPEG Version 2.5)
-- C - Layer description (eg 01 - Layer III)
-- D - Protection Bit (eg 1 - No protection)
-- EEEE - Bit rate (eg 0110 - 192kbps)
Frame sync: 11111111111
MPEG Audio Version: 10
Layer description: 01
Protection Bit: 1
Bit rate: 1111
We can see in this case we have a frame sync, an MPEG Audio version of 10, and a bit rate defined with 1111.
Digital forensics analysis
Now we can search the whole of an MP3 file and determine the places that we find 12 1’s, and see how often this occurs. Figure 4 shows a sample run, and where we have found “FE” in all of the 512-byte data segments of the file.

ID3 header
MP3 files now often come with an ID3 header, and which gives details of the song, such as its title, the artist and its genre (00- Blues, 01- Classic Rock, 02- Country, and so on [here]). An example is [here]:

Now we can analyse this using the following C# code:
The format is the ID3 header is thus:
header 3 "TAG" title 30 30 characters of the title artist 30 30 characters of the artist name album 30 30 characters of the album name year 4 A four-digit year comment 28[3] or 30 The comment. zero-byte[3] 1 If a track number is stored, this byte contains a binary 0. track[3] 1 The number of the track on the album, or 0. Invalid, if previous byte is not a binary 0. genre 1 Index in a list of genres, or 255
In this case, we have three bytes for “ID3”, followed by 30 bytes for the title, and 30 bytes for the artist, and also 30 bytes for the album. The year follows as a four-byte string. We can see we also have a track number, and a genre (one byte).
If you want to analyse more, try here: