MP4 is a video format which integrates the MPEG video encoding standard. This page uses ffmpeg.exe to determine the basic coding details of different MP4 files. The format used is:
ffmpeg -i file.mp4
MPEG-4MP4 is a video format which integrates the MPEG video encoding standard. This page uses ffmpeg.exe to determine the basic coding details of different MP4 files. The format used is: ffmpeg -i file.mp4 |
Motion video contains massive amounts of redundant information. This is because each image has redundant information and because there are very few changes from one image to the next. Motion video image compression relies on two facts:
As with JPEG, the Motion Picture Experts Group (MPEG) was setup to develop an interna-tional open standard for the compression of high-quality audio and video information. At the time, CD-ROM single-speed technology allowed a maximum bit rate of 1.2 Mbps and this was the rate that the standard was built around. These days, x12 and x20 CD-ROM bit rates are common, which allow for smoother and faster animations.
MPEG’s main aim was to provide good quality video and audio using hardware proces-sors (and in some cases, on workstations with sufficient computing power, to perform the tasks using software). Figure 1 shows the main processing steps of encoding:
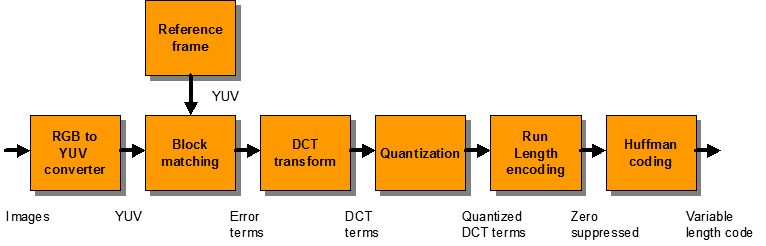
Figure 11.1 MPEG encoding with block matching
MPEG-1 typically uses the CIF format for its input, which has the following parameters:
This gives a picture quality which is similar to VCR technology. MPEG-1 differs from con-ventional TV in that it is non-interlaced (known as progressive scanning), but the frame rate is the same as conventional TV, i.e. 25fps (for PAL and SECAM) and 30fps (for NSTC). Note that MPEG-1 can also use larger pixel frames, such as CCIR-601 740480, but the CIF format is the most frequency used.
Taking into account the interlacing effect, the CIF format is actually derived from the CCIR-601 format. The CCIR-601 digital television standard defines a picture size of 720x243 (or 240) by 60 fields per second. Note that a frame actually comprises two fields, where the odd and even information is interlaced to create the full picture. When the interlaced luminance information occupies the full 720x480 frame, the chrominance components are reduced by 4:2:2 subsampling to give 360x243 (or 240) by 60 fields per second.
MPEG-1 also reduces the chrominance components by reducing the pixel data by half in the vertical, horizontal and time directions. It also reduces the image size so that the number of pixels for it is divisible by 8 or 16. This is because the motion analysis and DCT conversion operate on x or 8x8 pixel blocks. As a result, the number of lines changes for an MPEG-1 encoded move between the NSTC standard and PAL and SECAM standards. The final figure for PAL and SECAM is 288 at 50fps; for NSTC it is 240 at 60fps. These require the same number of bits to encode the streams.
The MPEG encoded bitstream comprises three components: compressed video, com-pressed audio and system-level information. To provide easier synchronization and lip synching the audio and video streams are time stamped using a 90kHz reference clock.
The first stage of MPEG encoding is to convert a video image into the correct color space format. In most cases, the incoming data is in 24-bit RGB color format and is converted in 4:2:2 YCrCb (or YUV) form. Some information will obviously be lost in the conversion of the color components, as there will only be half the number of samples for the redness and the blueness as there is for the luminance, but it results in some compression.
MPEG compression tries to detect movement within a frame. This is done by subdividing a frame into slices and then subdividing each slice into a number of macroblocks. For exam-ple, a PAL format which has:
352x288 pixel frame (101376 pixels)
can, when divided into 16x16 blocks, give a whole number of 396 macroblocks. Dividing 288 by 16 gives a whole number of 18 slices, and dividing 352 gives 22. Thus the image is split into 22 macroblocks in the x-direction and 18 in the y-direction, as illustrated in Figure 2.
Luminance (Y) values use a 16x16 pixel macroblock, whereas the two chrominance components have 8x8 pixel macroblocks. Note that only the luminance component is used for the motion calculations, as motion that is detected in the luminance components is likely to be the same as the one in the redness and blueness components.

Figure 2 Segmentation of an image into subblocks
MPEG uses a motion estimation algorithm to search for multiple blocks of pixels within a given search area and tries to track objects which move across the image. Each luminance (Y) 1616 macroblock is compared with other macroblocks within either a previous or fu-ture frame to find a close match. When a close match is found, a vector is used to describe where the block is to be located, as well as any difference information from the compared block. As there tends to be very few changes from one frame to the next, it is far more efficient than using the original data.
Figure 3 shows two consecutive images of 2D luminance made up into 165 mega-blocks. Each of these blocks has 1616 pixels. It can be seen that, in this example, there are very few differences between the two images. If the previous image is transmitted in its en-tirety then the current image can be transmitted with reference to the previous image. For example, the megablocks for (0,0), (0,1) and (0,2) in the current block are the same as in the previous blocks. Thus they can be coded simply with a reference to the previous image. The (0,3) megablock is different to the previous image, but the (0,3) block is identical to the (0,2) block of the previous image, thus a reference to this block is made. This can continue, as most of the blocks in the image are identical to the previous image. The only other differ-ences in the current image are at (4,0) and (4,1); these blocks can be stored in their entirety or specified with their differences to a previous similar block. A major objective of the MPEG encoder is to spend a much greater time compressing the video information into its most efficient form. Each macroblock is compared mathematically with other blocks in a previous frame, or even in a future frame. The offset information to another block can be over a macroblock boundary or even over a pixel boundary. This comparison then repeats until a match is found or the specified search area within the frame has been exhausted. If no match is available, the search process can be repeated using a different frame, or the macroblock can be stored as a complete set of data. As previously stated, if a match is found, the vector information specifying where the matching macroblock is located is used along with any difference information.
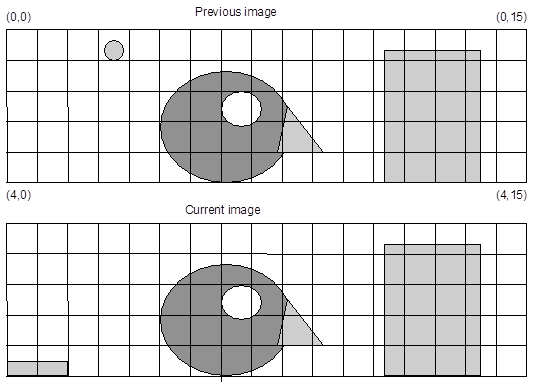
Figure 3 Two consecutive images
As the technique involves many searches over a wide search area and there are many frames to be encoded, the encoder must normally be a high-powered workstation. This has several implications:
With the motion estimation completed, the raw data describing the frame is now converted by DCT algorithm to be ready for Huffman coding.
As video frames tend not to change much between frames, MPEG video compression uses either full frames (which contain all the frame data), or partial frames (which refer back to other frames). The three frames types are defined as: