Hashing (Simularity)
Similarity hashes allow for two data objects to be compared for their similarity.
|

 [
[Theory
Roussev [1] defines a range of methods that can be used to find similarity:
- Finding known objects (Basic hashing). This includes the well known cryptographic hashing methods, such as MD5, SHA-1, SHA-256 and SHA-3. These hashes are well optimized, and aim to produce a random change of output bits for any changes in the input bits.
- Hash set presentations (Bloom filters).
-
Finding similar objects (Data Fingerprints). This includes similarity hashing, which has a base around spam filtering. Similarity hashing can be broken in to two main categories [2]:
- Binary Approximate Matching - Where similarity determinations are made at the binary level.
- Semantic Approximate Matching - where similarity is a function of the perceived content, be it textual (e.g. Google search), visual (e.g. reverse image lookup), or audio based (e.g. Shazam) similarities.
Binary approaches are poor at dealing with changes in file encoding or format, but are useful for matching image fragments, or files with very mismatched sizes (with some solutions focusing heavily on this latter aspect [3]. Semantic approaches are typically robust to many transfor- mations and file re-encoding, but are computationally expensive [2], and may generate many false positives [4].
A typical method of detecting the similarity of images is to extra different features from an image, such as related to the average luminosity and the detection of background colours, and then to hash these values. Next, these hashes are then compared with other image hashes, and the measure the distance between the hashes:
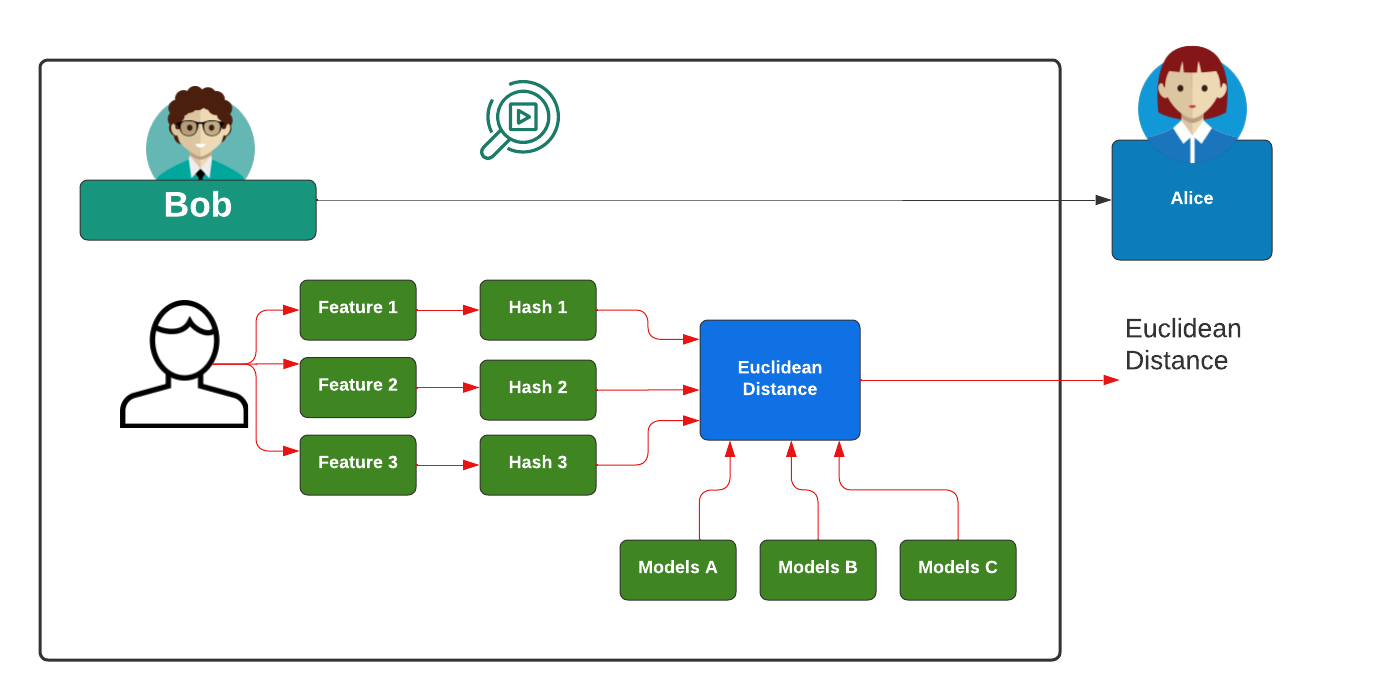
It should be noted that there are a wide range of non-cryptographic methods which provide a fast way of hashing data, without the strong requirements around security. Google recommend the following for 64-bit hashes without quality problems [5]: xxh3low; wyhash; ahash64; t1ha2_atonce; FarmHash; halftime_hash128; Spooky32; pengyhash; nmhash32; mx3; MUM/mir; and fasthash32.
References
[1] V. Roussev, “Hashing and data fingerprinting in digital forensics,” IEEE Security & Privacy, vol. 7, no. 2, pp. 49–55, 2009.
[2] F. Breitinger, H. Liu, C. Winter, H. Baier, A. Rybalchenko, and M. Steinebach, “Towards a process model for hash functions in digital forensics,” in International Conference on Digital Forensics and Cyber Crime. Springer, 2013, pp. 170–186.
[3] V. Roussev, G. G. Richard III, and L. Marziale, “Multi-resolution similarity hashing,” digital investigation, vol. 4, pp. 105–113, 2007.
[4] S. McKeown, G. Russell, and P. Leimich, “Fast Forensic Triage Using Centralised Thumbnail Caches on Windows Operating Systems,” Journal of Digital Forensics, Security and Law, vol. 14, no. 3, p. 1, 2019.[Online]. Available: https://commons.erau.edu/jdfsl/vol14/iss3/1
[5] W. J. Buchanan. Hashing (non-cryptographic). Asecuritysite.com.[Online]. Available: https://asecuritysite.com/hash2
[6] Kornblum, J. (2006). Identifying almost identical files using context triggered piecewise hashing. Digital investigation, 3, 91-97.
[7] Oliver, J., Cheng, C., & Chen, Y. (2013, November). TLSH - a locality sensitive hash. In 2013 Fourth Cybercrime and Trustworthy Computing Workshop (pp. 7–13). IEEE.