Nilsimsa is a similarity hash which is used as an anti-spam focused locality-sensitive hashing method [here]. This produces a score from 0 (dissimilar objects) to 128 (identical or very similar objects).
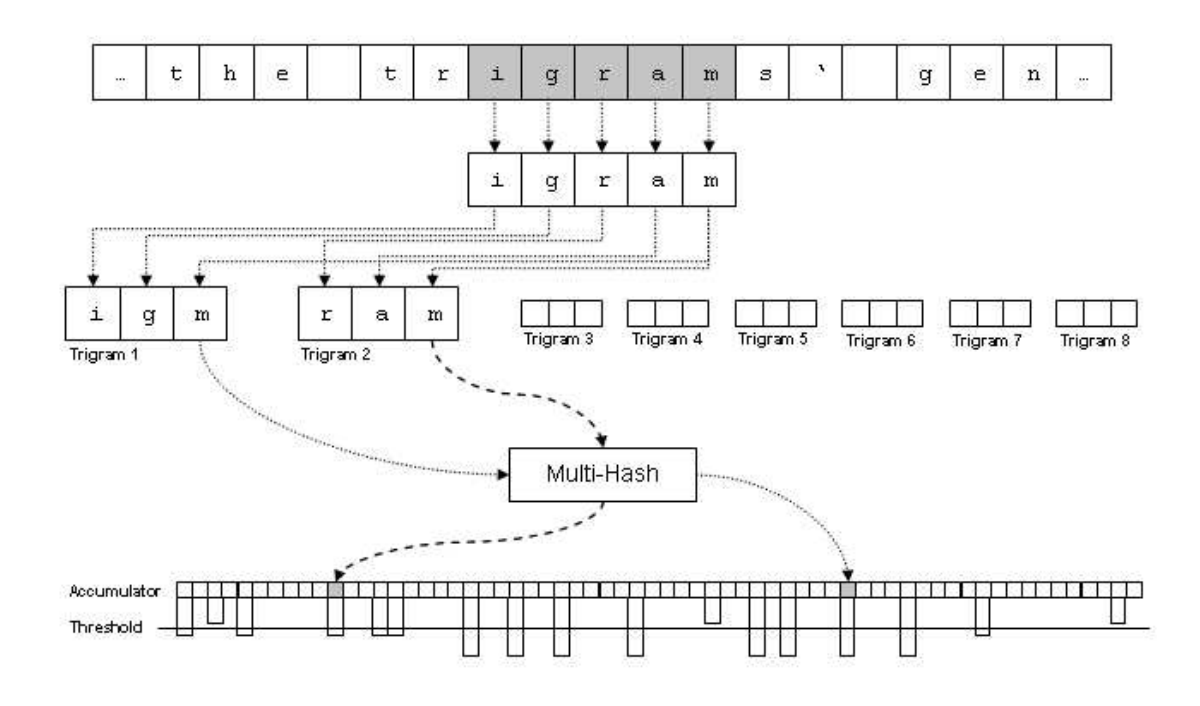
Nilsimsa similarity hashTheoryNilsima was created Damiani et al. in order to detect spam emails [here]. It uses a 5-byte fixed-size sliding window that analyses the input on a byte-by-byte and produces trigrams of possible combinations of the input characters. The trigrams map into a 256-bit array (known as the accumulator) to create the hash, and every time a given position is accessed, its value is incremented. At the end of the processing, if the values are above a certain threshold, the value is set to a 1, else it will be zero. This produces a 32-byte digest To compare two hashes, the method checks the number of identical bits red to the the same position. This produces a score from 0 (dissimilar objects) to 128 (identical or very similar objects).
A sample run is: Nilsimsa method String 1: Dear Bill, You have won £10,000,000. Please email me back. String 2: Dear Mark, You have won £10,000,000. Please email me back. -------------- String 1 digest: 28af87350c35cd842f13c9bd70ba24e232aedc1e7610cef4ed436f342ba82afb String 2 digest: 28af87370e25cd842f17c9bd62ba20e212aadc0e7690ced5e9036f342bac221b Score: 108 A sample table of scoring is:
CodingAn example of the coding is [here]:
import sys
if sys.version_info[0] >= 3:
PY3 = True
text_type = str
else:
PY3 = False
text_type = unicode
def is_iterable_non_string(obj):
return hasattr(obj, '__iter__') and not isinstance(obj, (bytes, text_type))
# $ Id: $
# table used in computing trigram statistics
# TRAN[x] is the accumulator that should be incremented when x
# is the value observed from hashing a triplet of recently
# seen characters (done in Nilsimsa.tran3(a, b, c, n))
TRAN = [ord(x) for x in
"\x02\xD6\x9E\x6F\xF9\x1D\x04\xAB\xD0\x22\x16\x1F\xD8\x73\xA1\xAC"\
"\x3B\x70\x62\x96\x1E\x6E\x8F\x39\x9D\x05\x14\x4A\xA6\xBE\xAE\x0E"\
"\xCF\xB9\x9C\x9A\xC7\x68\x13\xE1\x2D\xA4\xEB\x51\x8D\x64\x6B\x50"\
"\x23\x80\x03\x41\xEC\xBB\x71\xCC\x7A\x86\x7F\x98\xF2\x36\x5E\xEE"\
"\x8E\xCE\x4F\xB8\x32\xB6\x5F\x59\xDC\x1B\x31\x4C\x7B\xF0\x63\x01"\
"\x6C\xBA\x07\xE8\x12\x77\x49\x3C\xDA\x46\xFE\x2F\x79\x1C\x9B\x30"\
"\xE3\x00\x06\x7E\x2E\x0F\x38\x33\x21\xAD\xA5\x54\xCA\xA7\x29\xFC"\
"\x5A\x47\x69\x7D\xC5\x95\xB5\xF4\x0B\x90\xA3\x81\x6D\x25\x55\x35"\
"\xF5\x75\x74\x0A\x26\xBF\x19\x5C\x1A\xC6\xFF\x99\x5D\x84\xAA\x66"\
"\x3E\xAF\x78\xB3\x20\x43\xC1\xED\x24\xEA\xE6\x3F\x18\xF3\xA0\x42"\
"\x57\x08\x53\x60\xC3\xC0\x83\x40\x82\xD7\x09\xBD\x44\x2A\x67\xA8"\
"\x93\xE0\xC2\x56\x9F\xD9\xDD\x85\x15\xB4\x8A\x27\x28\x92\x76\xDE"\
"\xEF\xF8\xB2\xB7\xC9\x3D\x45\x94\x4B\x11\x0D\x65\xD5\x34\x8B\x91"\
"\x0C\xFA\x87\xE9\x7C\x5B\xB1\x4D\xE5\xD4\xCB\x10\xA2\x17\x89\xBC"\
"\xDB\xB0\xE2\x97\x88\x52\xF7\x48\xD3\x61\x2C\x3A\x2B\xD1\x8C\xFB"\
"\xF1\xCD\xE4\x6A\xE7\xA9\xFD\xC4\x37\xC8\xD2\xF6\xDF\x58\x72\x4E"]
# table used in comparing bit differences between digests
# POPC[x] = < number of 1 bits in x >
# so...
# POPC[a^b] = < number of bits different between a and b >
POPC = [ord(x) for x in
"\x00\x01\x01\x02\x01\x02\x02\x03\x01\x02\x02\x03\x02\x03\x03\x04"\
"\x01\x02\x02\x03\x02\x03\x03\x04\x02\x03\x03\x04\x03\x04\x04\x05"\
"\x01\x02\x02\x03\x02\x03\x03\x04\x02\x03\x03\x04\x03\x04\x04\x05"\
"\x02\x03\x03\x04\x03\x04\x04\x05\x03\x04\x04\x05\x04\x05\x05\x06"\
"\x01\x02\x02\x03\x02\x03\x03\x04\x02\x03\x03\x04\x03\x04\x04\x05"\
"\x02\x03\x03\x04\x03\x04\x04\x05\x03\x04\x04\x05\x04\x05\x05\x06"\
"\x02\x03\x03\x04\x03\x04\x04\x05\x03\x04\x04\x05\x04\x05\x05\x06"\
"\x03\x04\x04\x05\x04\x05\x05\x06\x04\x05\x05\x06\x05\x06\x06\x07"\
"\x01\x02\x02\x03\x02\x03\x03\x04\x02\x03\x03\x04\x03\x04\x04\x05"\
"\x02\x03\x03\x04\x03\x04\x04\x05\x03\x04\x04\x05\x04\x05\x05\x06"\
"\x02\x03\x03\x04\x03\x04\x04\x05\x03\x04\x04\x05\x04\x05\x05\x06"\
"\x03\x04\x04\x05\x04\x05\x05\x06\x04\x05\x05\x06\x05\x06\x06\x07"\
"\x02\x03\x03\x04\x03\x04\x04\x05\x03\x04\x04\x05\x04\x05\x05\x06"\
"\x03\x04\x04\x05\x04\x05\x05\x06\x04\x05\x05\x06\x05\x06\x06\x07"\
"\x03\x04\x04\x05\x04\x05\x05\x06\x04\x05\x05\x06\x05\x06\x06\x07"\
"\x04\x05\x05\x06\x05\x06\x06\x07\x05\x06\x06\x07\x06\x07\x07\x08"]
class Nilsimsa(object):
"""Nilsimsa code calculator."""
def __init__(self, data=None):
"""Nilsimsa calculator, w/optional list of initial data chunks."""
self.count = 0 # num characters seen
self.acc = [0]*256 # accumulators for computing digest
self.lastch = [-1]*4 # last four seen characters (-1 until set)
if data:
if is_iterable_non_string(data):
for chunk in data:
self.update(chunk)
elif isinstance(data, (bytes, text_type)):
self.update(data)
else:
raise TypeError("Excpected string, iterable or None, got {}"
.format(type(data)))
def tran3(self, a, b, c, n):
"""Get accumulator for a transition n between chars a, b, c."""
return (((TRAN[(a+n)&255]^TRAN[b]*(n+n+1))+TRAN[(c)^TRAN[n]])&255)
def update(self, data):
"""Add data to running digest, increasing the accumulators for 0-8
triplets formed by this char and the previous 0-3 chars."""
for character in data:
if PY3:
ch = character
else:
ch = ord(character)
self.count += 1
# incr accumulators for triplets
if self.lastch[1] > -1:
self.acc[self.tran3(ch, self.lastch[0], self.lastch[1], 0)] +=1
if self.lastch[2] > -1:
self.acc[self.tran3(ch, self.lastch[0], self.lastch[2], 1)] +=1
self.acc[self.tran3(ch, self.lastch[1], self.lastch[2], 2)] +=1
if self.lastch[3] > -1:
self.acc[self.tran3(ch, self.lastch[0], self.lastch[3], 3)] +=1
self.acc[self.tran3(ch, self.lastch[1], self.lastch[3], 4)] +=1
self.acc[self.tran3(ch, self.lastch[2], self.lastch[3], 5)] +=1
self.acc[self.tran3(self.lastch[3], self.lastch[0], ch, 6)] +=1
self.acc[self.tran3(self.lastch[3], self.lastch[2], ch, 7)] +=1
# adjust last seen chars
self.lastch = [ch] + self.lastch[:3]
def digest(self):
"""Get digest of data seen thus far as a list of bytes."""
total = 0 # number of triplets seen
if self.count == 3: # 3 chars = 1 triplet
total = 1
elif self.count == 4: # 4 chars = 4 triplets
total = 4
elif self.count > 4: # otherwise 8 triplets/char less
total = 8 * self.count - 28 # 28 'missed' during 'ramp-up'
threshold = total / 256 # threshold for accumulators, using the mean
code = [0]*32 # start with all zero bits
for i in range(256): # for all 256 accumulators
if self.acc[i] > threshold: # if it meets the threshold
code[i >> 3] += 1 << (i&7) # set corresponding digest bit, equivalent to i/8, 2 ** (i % 8)
return code[::-1] # reverse the byte order in result
def hexdigest(self):
"""Get digest of data seen this far as a 64-char hex string."""
return ("%02x" * 32) % tuple(self.digest())
def __str__(self):
"""Show digest for convenience."""
return self.hexdigest()
def from_file(self, filename):
"""Update running digest with content of named file."""
f = open(filename, 'rb')
while True:
data = f.read(10480)
if not data:
break
self.update(data)
f.close()
def compare(self, otherdigest, ishex=False):
"""Compute difference in bits between own digest and another.
returns -127 to 128; 128 is the same, -127 is different"""
bits = 0
myd = self.digest()
if ishex:
# convert to 32-tuple of unsighed two-byte INTs
otherdigest = tuple([int(otherdigest[i:i+2],16) for i in range(0,63,2)])
for i in range(32):
bits += POPC[255 & myd[i] ^ otherdigest[i]]
return 128 - bits
str1="hello"
str2="hel90"
print("Nilsimsa method")
print "String 1:\t",str1
print "String 2:\t",str2
print "\n--------------"
n1 = Nilsimsa()
n1.update(str1)
n2 = Nilsimsa(str2)
print "String 1 digest:",str(n1.hexdigest())
print "String 2 digest:",str(n2.hexdigest())
print "Score:\t",str(n1.compare(n2.digest()))
| |||||||||||||||||||||||||
 [
[